Replicator#
Omniverse Replicator is a framework for developing custom synthetic data generation pipelines and services. Developers can generate physically accurate 3D synthetic data that serves as a valuable way to enhance the training and performance of AI perception networks used in autonomous vehicles, robotics and intelligent video analytics applications.
Replicator is designed to easily integrate with existing pipelines using open-source standards like Universal Scene Description (USD), PhysX, and Material Definition Language (MDL). An extensible registry of annotators and writers is available to address specific requirements for training AI models.
Omniverse Replicator is exposed as a set of extensions, content, and examples in Omniverse Code and Isaac Sim. For a detailed presentation of Replicator, check out this talk.
The Replicator Tutorials section below covers high level aspects of getting started developing with Synthetic Data and Replicator.
Theory Behind Training with Synthetic Data#
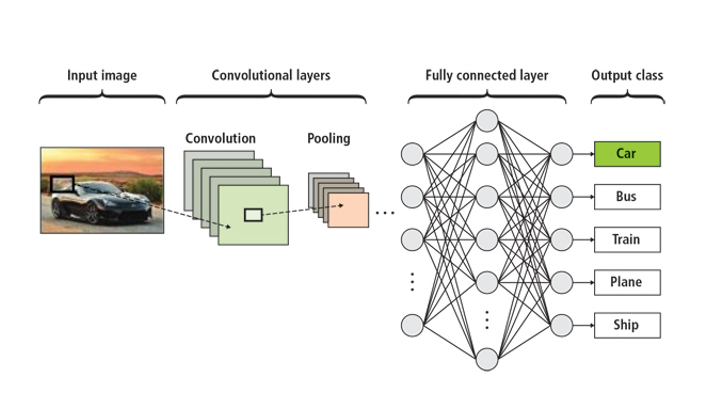
To train a deep neural network (DNN) for perception tasks, large sets of annotated images are needed. The DNNs are then trained for the perception tasks such as detection, classification and segmentation. To achieve the required KPIs, hyperparameters are fine-tuned through an iterative process. In most cases, this may not be sufficient, requiring a “data-centric” approach where new and diverse types of data may be needed to increase the desired performance of the model. However, collecting and annotating new data manually is an expensive process.
In such scenarios where data is limited, restricted, or simply doesn’t exist, synthetic data can help bridge that gap for developers in a cost-effective manner. Furthermore, synthetic data generation also addresses challenges related to long tail anomalies and edge use cases that are impossible to collect in the real-world.
Some more difficult perception tasks require annotations of images that are extremely difficult to do manually (e.g. images with occluded objects). Programmatically generated synthetic data can address this very effectively since all generated data is perfectly labeled. The programmatic nature of data generation also allows the creation of non-standard annotations and indirect features that can be beneficial to DNN performance.
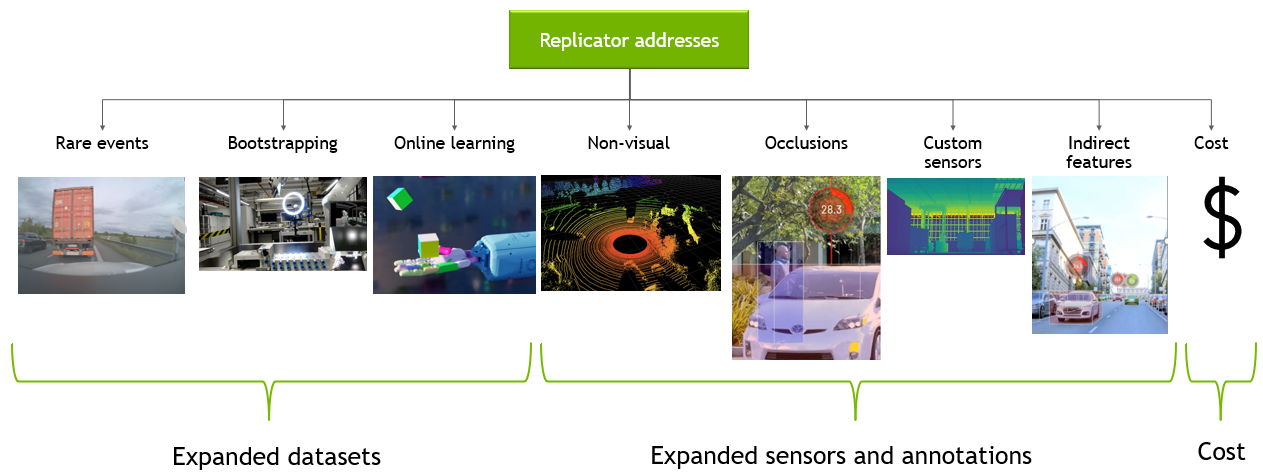
As described above, synthetic data generation has many advantages. However, there are a set of challenges that need to be addressed for it to be effective.
Closing the Simulation to Real Gap#
To bridge the gap between simulation and reality in synthetic data generation, we must address two distinct challenges known as the domain gap: the appearance gap and the content gap.
Appearance Gap: This pertains to disparities at the pixel level between real and synthetic images. Such differences can arise from variations in object intricacy, materials used, or limitations of the rendering system employed in synthetic data creation.
Content Gap: This encompasses variations in the domains themselves. Factors such as the quantity of objects present in a scene, the diversity in their types and placements, and other contextual elements contribute to the content gap between synthetic and real-world data.
Closing these gaps is vital to ensure that synthetic datasets accurately reflect real-world scenarios, enabling more effective training of AI models. Addressing the appearance gap involves refining rendering techniques and material representation, while mitigating the content gap requires enhancing the diversity and complexity of simulated scenes. By narrowing these gaps, we can improve the fidelity and applicability of synthetic data for training AI systems across various domains.
Overcoming domain gaps is crucial, and domain randomization plays a key role in this endeavor. By expanding the range of synthetic data generated, we aim to closely mirror real-world scenarios, including rare occurrences. This broader dataset distribution enables neural networks to better grasp the full complexity of the problem, enhancing their ability to generalize effectively.
Addressing the appearance gap involves leveraging high-fidelity 3D assets and advanced rendering techniques like ray-tracing or path-tracing. Physically based materials, such as those defined with the MDL material language, contribute to realism. Additionally, validated sensor models and randomized parameters aid in narrowing the appearance gap further.
To ensure content relevance, a diverse pool of assets tailored to the scene is indispensable. Platforms like Omniverse offer connectors to various 3D applications, facilitating asset integration. Developers can also devise tools to generate varied domain scenes pertinent to their specific context.
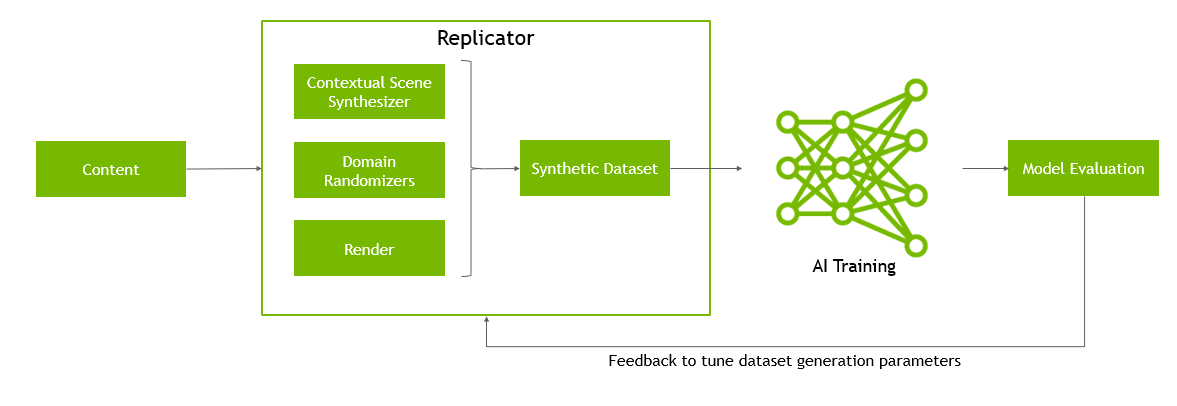
However, training with synthetic data introduces complexity, as it’s challenging to ascertain whether the randomizations adequately represent the real domain. Testing the network on real data is essential to validate its performance. Prioritizing a data-centric approach allows for fine-tuning the dataset before considering adjustments to model architecture or hyperparameters, addressing any performance issues effectively.
Core Components#
Replicator is composed of six components that enable you to generate synthetic data:
Semantics Schema Editor Semantic annotations (data “of interest” pertaining to a given mesh) are required to properly use the synthetic data extension. These annotations inform the extension about what objects in the scene need bounding boxes, pose estimations, etc… The Semantics Schema Editor provides a way to apply these annotations to prims on the stage through a UI.
Visualizer The Replicator visualizer enables you to visualize the semantic labels for 2D/3D bounding boxes, normals, depth and more.
Randomizers: Replicator’s randomization tools allow developers to easily create domain randomized scenes, quickly sampling from assets, materials, lighting, and camera positions.
Omni.syntheticdata: Omni.syntheticdata is the lowest level component of the Replicator software stack, and it will ship as a built-in extension in all future versions of the Omniverse Kit SDK. The omni.syntheticdata extension provides low level integration with the RTX renderer, and the OmniGraph computation graph system.This is the component that powers the computation graphs for Replicator’s Ground Truth extraction Annotators, passing Arbitrary Output Variables or AOVs from the renderer through to the Annotators.
Annotators: The annotation system itself ingests the AOVs and other output from the omni.syntheticdata extension to produce precisely labeled annotations for DNN training.
Writers: Writers process the images and other annotations from the annotators, and produce DNN specific data formats for training. Writers can output to local storage, over the network to cloud based storage backends such as SwiftStack, and in the future we will provide backends for live on-GPU training, allowing generated data to stay on the GPU for training and avoiding any additional IO at all.
Throughout generation of a dataset the most common workflow is to randomize a scene, select your annotators, and then write to your desired format. However, if needed for more customization you have access to omni.synthetic data.
API documentation and Changelogs#
Python API Documentation for Omniverse Replicator can be found here.
Changelogs for Omniverse Replicator are available at this link.
Replicator Examples on Github#
We now offer convenient Replicator Examples on Github. There are snippets, full scripts, and USD scenes where content examples are needed. This repo will grow as we add to it.
Courses and Videos#
Replicator Tutorials#
To help you get started with Replicator, we have created a handful of hands-on tutorials.
- Getting started with Replicator
- Core functionalities - "Hello World" of Replicator
- Camera Examples
- Running Replicator headlessly
- Adding semantics with Semantics Schema Editor and programmatically
- Interactive live visualization
- Randomizers examples
- Data Augmentation
- Replicator Materials
- Annotating with Transparent Materials
- Annotators information
- Visualizing output folder with annotated data programmatically
- Using existing 3D assets with Replicator
- Using Replicator with a fully developed scene
- Using physics with Replicator
- Randomizing appearance, placement and orientation of existing 3D assets with a built-in writer
- Writer Examples
- Create a custom writer
- Distribution Examples
- Rendering with Subframes
- I/O Optimization Guide
- Advanced Scattering
- Working with Layers
- Replicator YAML
- Replicator YAML Manual and Syntax Guide
Replicator On Cloud#
Instructions are given for setting up Replicator on cloud below.
Known Issues#
Materials or textures will sometimes not be loaded in time for capture when in
RTX - Real-Timemode. If this occurs, you can increase the interval between captures by setting the/omni/replicator/RTSubframesflag (default=3). To set in Python,carb.settings.get_settings().set(<new value>). Similarly, capture speed can be increased if no materials are randomized by setting the value to its minimum of 1.Errors in annotator visualization and data generation may occur when running on a system with multi-GPU. To disable multi-GPU, launch with the
--/renderer/multiGpu/enabled=falseflag.In scenes with a large number of 3D bounding boxes, the visualizer flickers due to the rendering order of the boxes. This rendering issue is purely aesthetic and will not have any effect when writing the data.
Tiled Sensor artifacts present in RGB output when assets are positioned on the up axis at 0.0 units.