Visualizing Semantic Data#
Learning Objectives#
This tutorial introduces the Synthetic Data interface for Replicator. After this tutorial, you will know how to define, apply, and visualize semantic data in Replicator.
Getting Started#
The Editor#
Semantic annotations (data “of interest” pertaining to a given mesh) are required to properly use the synthetic data extension. These annotations inform the extension about what objects in the scene need bounding boxes, pose estimations, etc… The Semantics Schema Editor provides a way to apply these annotations to prims on the stage through a UI.
To access the editor, follow the steps detailed in Adding Semantics to a Scene. The editor will appear as a tab in the Properties pane by default.
Semantic annotations can be applied either manually to a collection of selected prims or automatically by the path and type of each prim on the stage
The Visualizer#
Visualizing the output of synthetic sensors is done through the  Visualizer tool in the Viewport window.
Visualizer tool in the Viewport window.
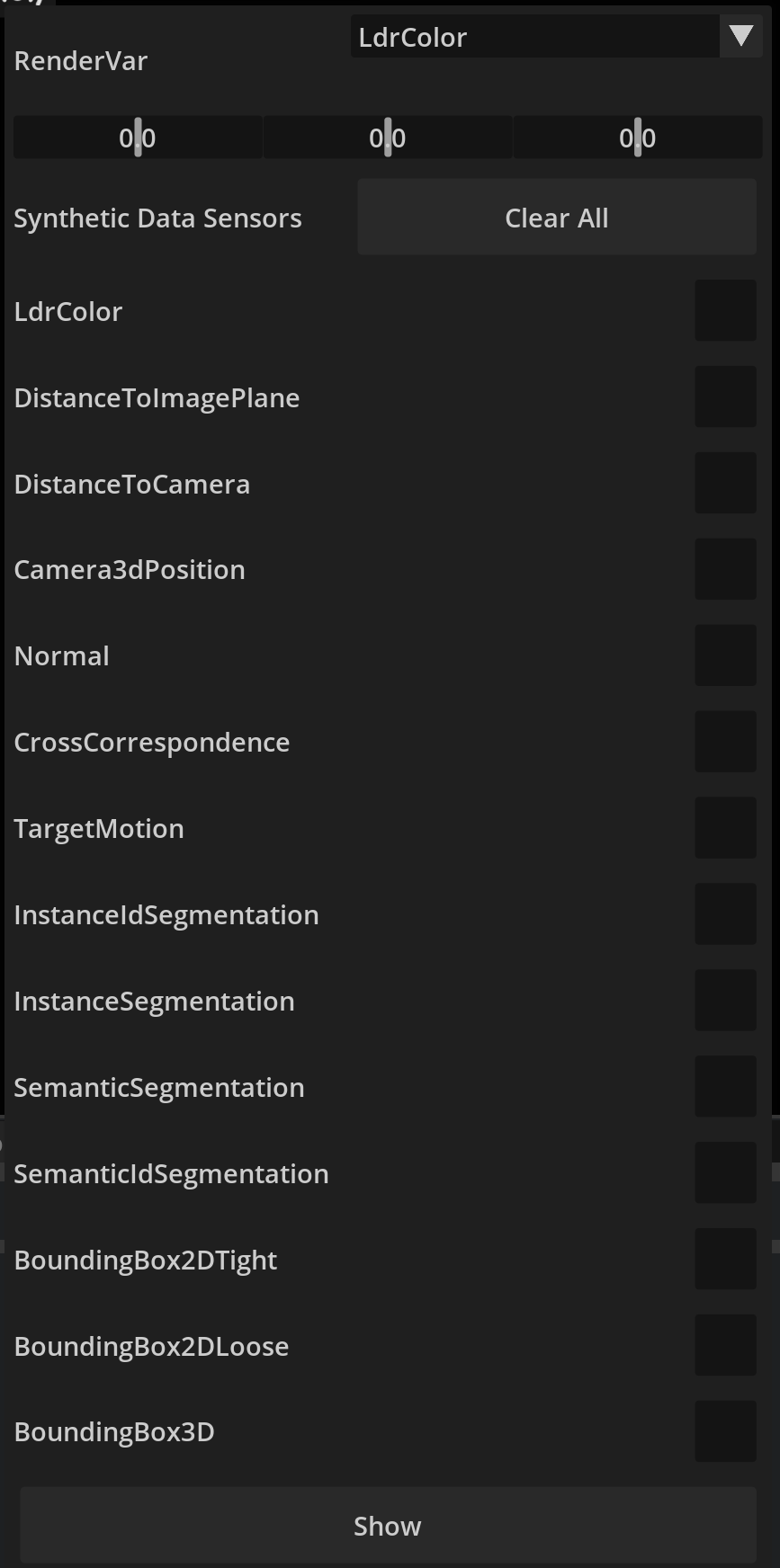
Annotations that can be rendered to an image are listed here. Activating a channel and pressing the visualize button will
render those channels in a test image, like the one shown below
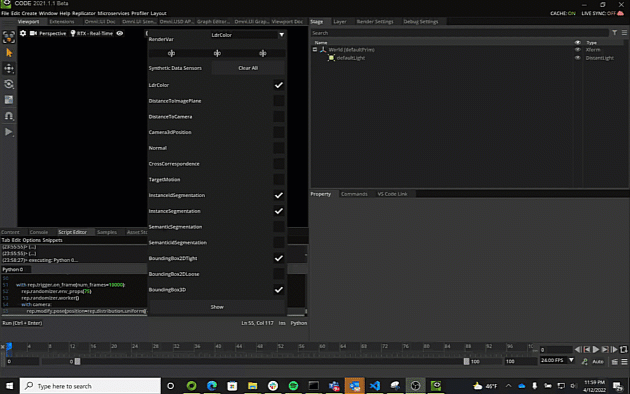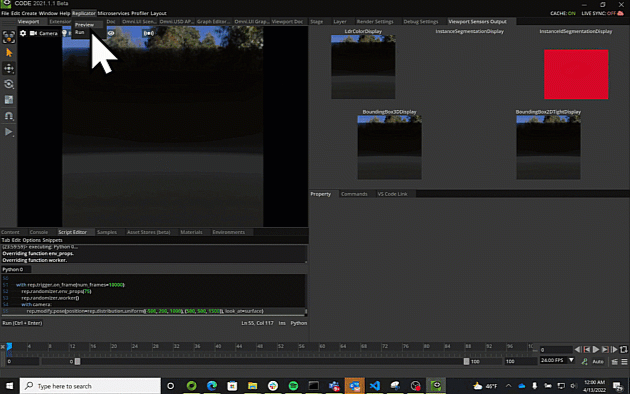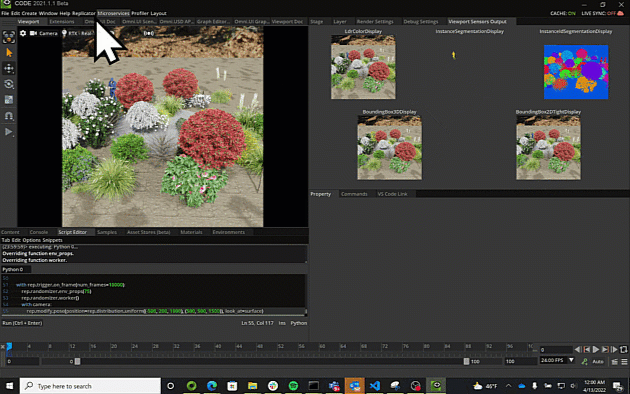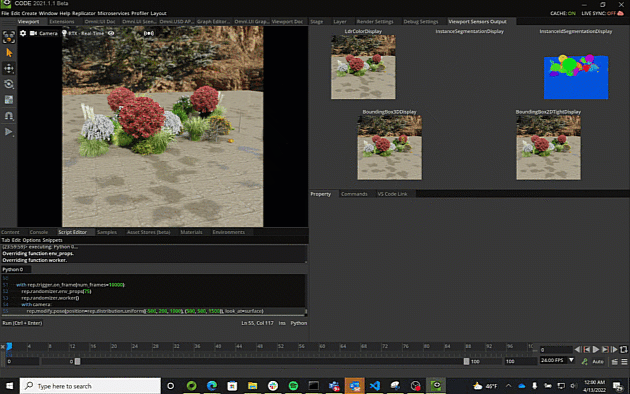
Note
If the camera name is too long, the
icon in the Viewport window might get obscured
LdrColor This is just the standard view from the viewport camera in RGB. Note that selected prims and the viewport grid are also captured by this camera, and need to be disabled manually in the adjacent ‘show/hide’ menu
DistanceToImagePlane Distance to the image plane is distance in the camera’s forward axis.
DistanceToCamera Distance to camera is a distance to the camera’s centre.
CrossCorrespondence CrossCorrespondence provides, given two cameras in two viewports, the difference in pixel positions for pixels that exist in both cameras.
Normals This colors each pixel corresponding to the direction each surface in the stage is facing
TargetMotion This is the optical flow, and only really applies to scenes with dynamics.
Semantic and Instance Segmentation
the 2D segmentation regions for each type of object in the scene, and each instance of each object in the scene respectively. Raw here means that semantics
are not inherited from parent prims, while Parsed does.
2D Bounding Boxes
2D bounding boxes are the 2D region in the image that holds an object with a semantic label. Tight means that the box will occlude or intersect parts
of the object to reduce the amount of space in the bbox that the object doesn’t occupy. Loose is the opposite, expanding the box to make sure that all
parts of the mesh are captured
3D Bounding Boxes
3D bounding boxes define a set of 8 points that define the corners of a 3D box that holds an object with a semantic label. Raw and Parsed here means the same
as it did for semantic segmentation.