Data Aggregation Best Practices#
When configuring your scene in USD, it’s important to plan ahead to ensure your aggregate datasets are legible, modular, performant, and navigable. Harness the power of USD by learning more about concepts like Layers, Instances, References, and Payloads.
Overview#
This guide is a high-level, conceptual overview of the import, aggregation, and optimization of USD datasets in Omniverse. Onboarding with these high-level best practices in USD will equip you to execute workflows like those in the diagram below, at scale to increasingly large datasets.
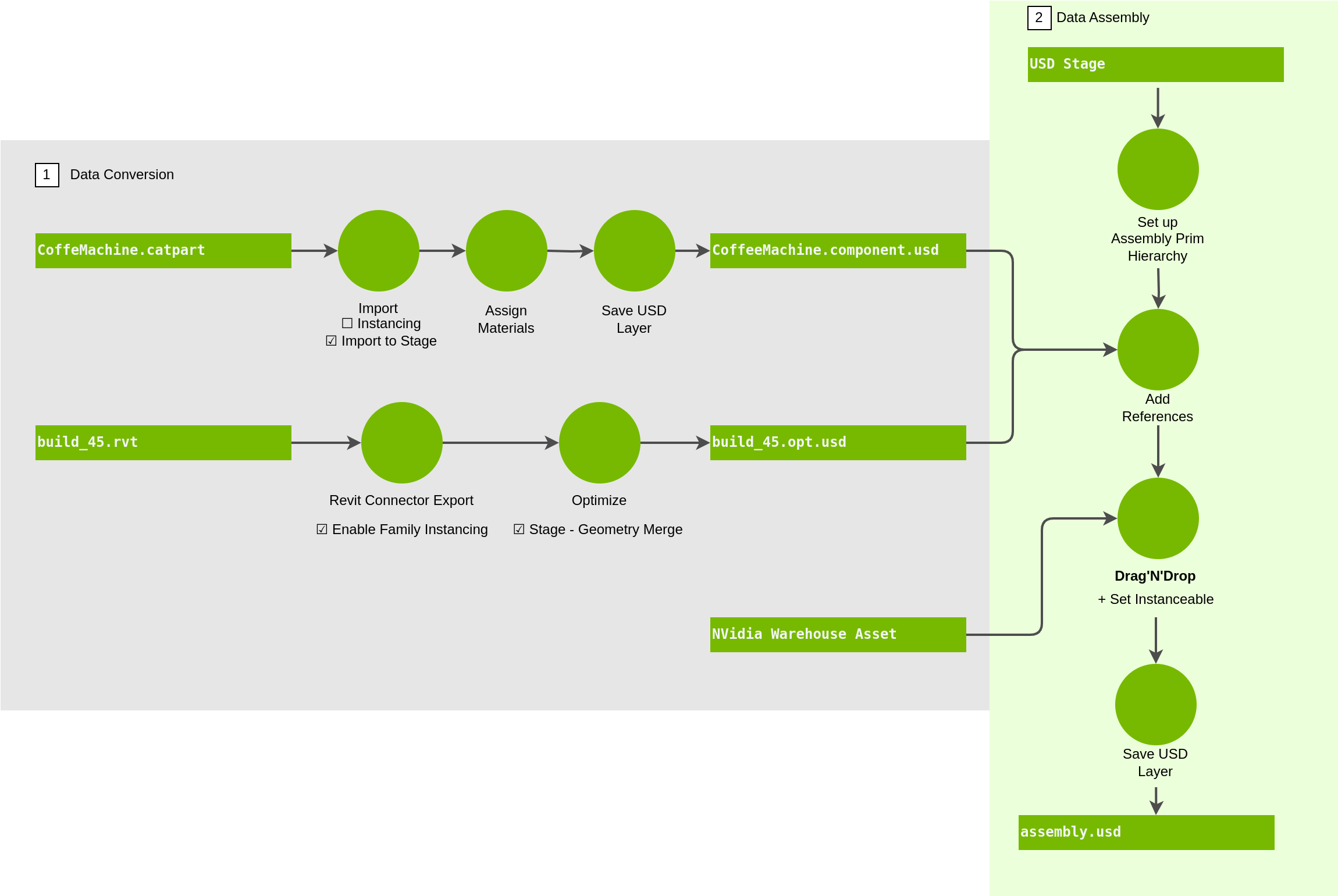
Data Import#
Here are some points to consider when importing datasets into USD Explorer.
Consider which of your datasets are to be edited as individual sources, and which datasets are aggregated from multiple sources.
An example for editing would be to reorganize a hierarchy of objects that was flat in the source data, for improved legibility and segmentation of to optimize for better performance.
An example for aggregating would be to place a safety fence, storage area, or robotic work cells into an industrial facility.
Edits on individual sources can picked up by aggregate datasets that are referencing them. For example, if you open a robot’s USD, change its material color, and save it, all USDs that reference that robot’s USD will pick up that material color change, unless they are overriding it.
Edits on datasets in aggregate can override edits on the individual source datasets being referenced without actually modifying the referenced data. For example, you can edit the aggregate dataset to change the material color on a referenced robot, without modifying the robot’s USD in the source that is being referenced. This is termed “non-destructive” editing in USD.
Aggregate datasets can themselves be aggregated into larger and larger datasets. For example, a parts rack can be an aggregate of many references of the source USD for the same part, such as a hood, and the USD for that hood rack can then also be referenced many times into a larger aggregate dataset representing your industrial facility.
Organizing your data bottom up will go a long way towards producing performant and navigable datasets at scale. That is, the more organized you are at the parts level all the way up to your entire facility, the easier it will be to reason about and work with the ever-growing amounts of data being aggregated.
See this document for some basic data import workflows.
USD Basics#
The following are some fundamental USD concepts to understand when organizing your datasets.
In OpenUSD, a virtual world:
is a composed
stage(scenegraph)of
prims(short for “primitives”, i.e., data containers)defined in
layers(underlying document model).
Prims are organized hierarchically.
Model Hierarchy is a “table of contents” for the entire dataset, partitioned into significant subsections.
Prims can reference prim hierarchies within the same layer or from other layers.
Payloads are like references, that can be unloaded and loaded from memory in your working session.
A layer can contain an ordered list of sublayers to segment workstream-specific data (e.g., layout, look development, animation). The order of the sublayers determines their composition strength ordering in the local layer stack, where data in stronger layers overrides data in weaker layers. The layer containing the sublayers is stronger than all of the sublayers.
Stronger layers can sparsely override or add to data coming from weaker layers
e.g., from sublayers, references, payloads, etc. without modifying the source content in the weaker layers (non-destructive editing)
For example, you can override just the material color on a referenced object while leaving all of its geometry intact (sparse overrides).
Similarly, stronger sublayers (i.e., sublayers that are higher in the Layer Window) can sparsely override data from weaker sublayers (i.e., sublayers that are lower in the Layer Window)
See these documents for details
Assemblies#
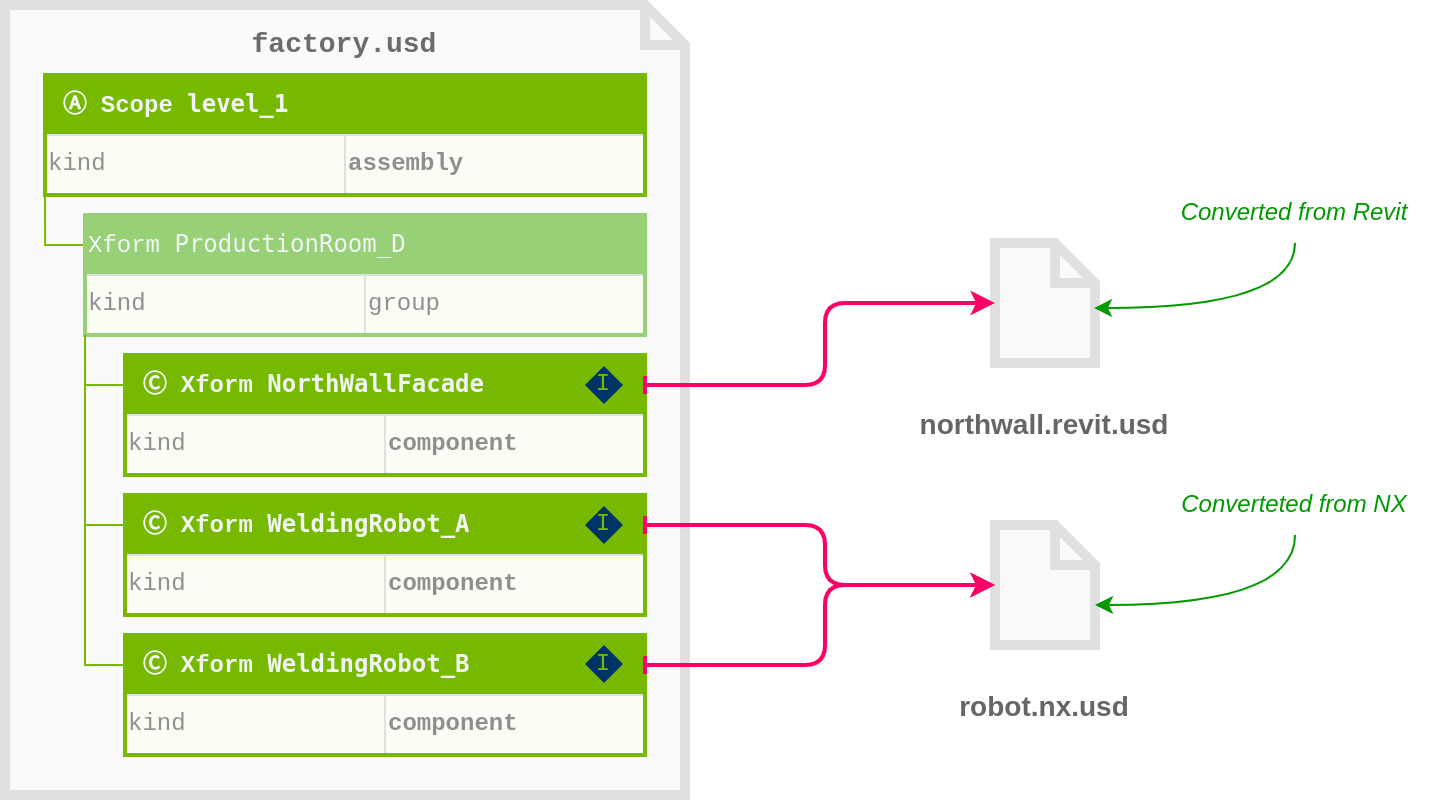
Assemblies are USD layers containing aggregate prim hierarchies intended for reuse in larger aggregates. This is a similar, but not an identical, concept to ‘assemblies’ in CAD.
e.g., a workcell is an assembly of multiple component hierarchies, that can itself be aggregated into a factory.
Referencing is utilized to bring other component models into the aggregate hierarchy.
References can be external (connecting prims from different layers) or internal (connecting prims that exist in the same layer).
See this document for more details on USD Assemblies for data aggregation.
Instances#
Think of instancing as leveraging “read-only” subsections of large datasets for maximum data sharing
In USD, prims can be marked as instanceable.
The instanceable metadata informs USD that prim hierarchies with identical references (and other “composition arcs”) should be treated as identical sub-hierarchies.
This makes instancing a very powerful tool for scene optimization, in particular speeding up traversal, for example when rendering.
There are tradeoffs to instancing however. Because instanceable prim hierarchies need to be identical, changes to individual prims within instances are not permitted.
For example, it’s not easily possible to transform a prim (e.g., rotate a tire) within an instanced car or change material assignments for a part within a specific instance of a robot.
See this document for a detailed description of Instancing.
Scene Optimization#
As with any large dataset, there are performance and navigability considerations when dealing with many individual objects.
The Scene Optimizer Extension provides various optimization operators which can be stacked and executed to streamline your datasets.
See this document to learn which Scene Optimization Presets may be most applicable to your content.
Further Learning#
Learn More about Principles of Scalable Asset Structure in OpenUSD.
Learn More about Layers.