Walkthrough: Franka Block Stacking
Note
Cortex is deprecated as of 4.1.0. Future versions will be independent of Isaac Sim.
This tutorial walks through a complete reactive block stacking application. This example builds the scene entirely using the Isaac Sim core python API and runs the behavior. See Walkthrough: UR10 Bin Stacking for an example of designing a behavior for an existing USD environment.
In all command line examples, we use the abbreviation isaac_python for the Isaac Sim python
script (<isaac_sim_root>/python.sh on Linux and <isaac_sim_root>\python.bat on Windows).
The command lines are written relative to the working directory
standalone_examplesomni/api/omni.isaac.cortex.
Run the following demo
isaac_python franka_examples_main.py --behavior=block_stacking_behavior
Press play once Isaac Sim has started up. You’ll see the Franka block stacking demo running.
This tutorial will step through the demo.
The environment has a Franka robot with a set of 4 blocks of different colors. Its goal is to stack the blocks into a tower in a pre-defined order. This behavior is reactive and robust to user interaction. Users can move the blocks as shown in the video and the robot will adapt as needed to continue progressing toward its goal.
Block stacking decider network
The decider network is shown in the figure below.
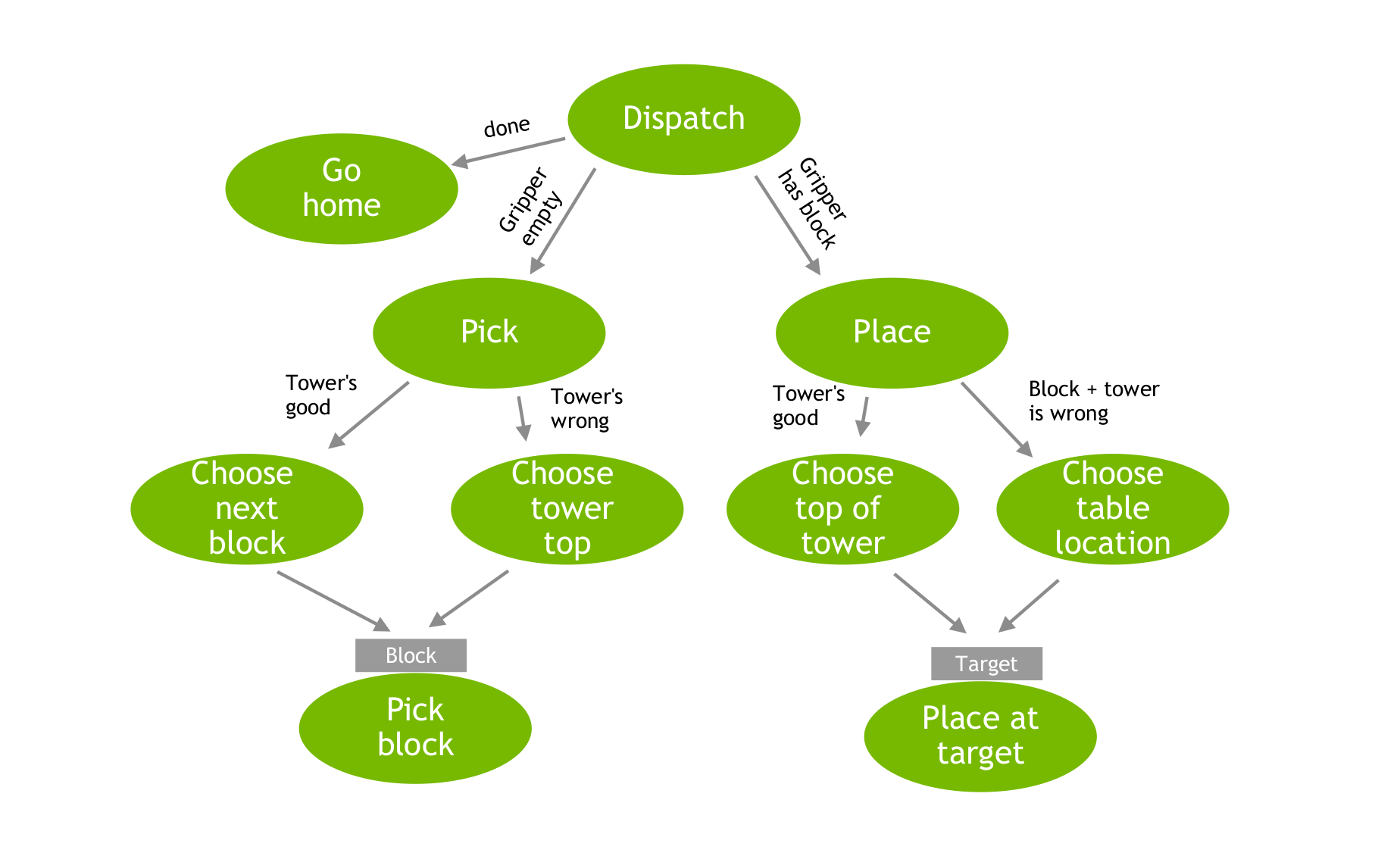
In words, the dispatch revolves around the state of the tower and the gripper. If the tower’s done, then go home. If there’s more work to do, if there’s a block in the gripper, place it somewhere. Otherwise, if there’s no block in the gripper, acquire a block. At the next level down, it decides where to place the block and which block to acquire. The pick block and place at target decider nodes (action nodes) are the same in all cases and key off parameters passed in from the decider nodes one level up.
Top-level dispatch
The behavior is constructed as a decider network:
def make_decider_network(robot):
return DfNetwork(
BlockPickAndPlaceDispatch(), context=BuildTowerContext(robot, tower_position=np.array([0.25, 0.3, 0.0]))
)
with top-level dispatch decider node BlockPickAndPlaceDispatch. The dispatch decider node’s
implementation is simple, directly modeling the logic shown in the above diagram:
class BlockPickAndPlaceDispatch(DfDecider):
def __init__(self):
super().__init__()
self.add_child("pick", make_pick_rlds())
self.add_child("place", make_place_rlds())
self.add_child("go_home", GoHome())
def decide(self):
ct = self.context
if ct.block_tower.is_complete:
return DfDecision("go_home")
if ct.is_gripper_clear:
return DfDecision("pick")
else:
return DfDecision("place")
If the tower’s complete, then go home. Otherwise, there’s more to do with the tower. If there’s nothing in the gripper (gripper clear) then pick up a block. Otherwise, there’s a block in the gripper, and place it somewhere. The rest is about both choosing what to pick or where to place the current block, and how to perform this specific action.
Each of these decisions map to the children setup on construction. Both the pick and place behaviors
are modeled as DfRldsDecider nodes as described next.
Robust Logical Dynamical Systems (RLDS)
Both the pick and place behaviors are modeled as Robust Logical Dynamical Systems (RLDS). See the RLDS paper on ArXiv. An RLDS is a sequence of behaviors, each of which has a entry condition on the logical state defining whether it’s runnable. The RLDS algorithm steps backward from the last behavior in the sequence checking each node’s runnability condition. It executes the first (most distal) behavior that says it’s runnable. In that sense, the more distal the behavior, the higher the priority. The sequence is known as its priority sequence.
See class DfRldsDecider for the RLDS implementation as a decider node. The decide() method
implements the reverse sweep through the RLDS sequence. See also Nathan Ratliff’s Isaac Cortex
GTC22 talk for additional
details on RLDSs.
The pick RLDS decider
The pick RLDS decider has three behaviors in its priority sequence.
def make_pick_rlds():
rlds = DfRldsDecider()
...
rlds.append_rlds_node("reach_to_block", reach_to_block_rd)
rlds.append_rlds_node("pick_block", PickBlockRd())
rlds.append_rlds_node("open_gripper", open_gripper_rd) # Always open the gripper if it's not.
return rlds
It’s most intuitive to read these nodes in reverse since that’s the order they’re processed by the RLDS algorithm. In order of highest priority to lowest priority (reverse order) we have:
Open gripper: If the gripper isn’t open, the highest priority action is to open the gripper.
Pick block: To get here, the gripper must be open. If the block is between the fingers, pick it.
Reach to block: To get here, the gripper is open but not at the block yet. Reach toward the block.
Each node in the sequence executes an action designed to drive the system toward satisfying the runnable condition of the next behavior in the sequence.
The decision of which block to pick is handled by the reach_to_block_rd node. It’s constructed
in the section of code hidden by the ... above:
open_gripper_rd = OpenGripperRd(dist_thresh_for_open=0.15)
reach_to_block_rd = ReachToBlockRd()
choose_block = ChooseNextBlock()
approach_grasp = DfApproachGrasp()
reach_to_block_rd.link_to("choose_block", choose_block)
choose_block.link_to("approach_grasp", approach_grasp)
It first chooses the block in a choose_block node, then passes the chosen block as parameters down to
approach_grasp. ChooseNextBlock itself has two possible children
ChooseNextBlockForTowerBuildUp and ChooseNextBlockForTowerTeardown, and the decision is made
based on whether the stack is currently in the right order.
The place RLDS decider
The place RLDS decider is similar in nature to the pick decider:
def make_place_rlds():
rlds = DfRldsDecider()
rlds.append_rlds_node("reach_to_placement", ReachToPlacementRd())
rlds.append_rlds_node("place_block", PlaceBlockRd())
return rlds
Again, ReachToPlacementRd itself decides where to place base on the current logical state of the
tower.
Pick and place atomic actions
The pick_block node is itself an state machine implemented by the PickBlockRd node. Its
state sequence is built on construction:
class PickBlockRd(DfStateMachineDecider, DfRldsNode):
def __init__(self):
# This behavior uses the locking feature of the decision framework to run a state machine
# sequence as an atomic unit.
super().__init__(
DfStateSequence(
[
DfSetLockState(set_locked_to=True, decider=self),
DfTimedDeciderState(DfCloseGripper(), activity_duration=0.5),
DfTimedDeciderState(Lift(0.1), activity_duration=0.25),
DfWriteContextState(lambda ctx: ctx.mark_block_in_gripper()),
DfSetLockState(set_locked_to=False, decider=self),
]
)
)
...
The state machine shouldn’t be interrupted to ensure successful grasps, so we make it atomic, by locking the decider network in the beginning and unlocking it in the end. Locking the decider network ensures that the decision path from the root to this node remain the same until it’s unlocked. If we didn’t do that, the higher-level dispatch could preempt this node half way through and prevent a successful pick. This model is the reverse of most other frameworks to promote reactivity. Everything is preemptable unless it’s specifically locked.
The full sequence for a pick is
Lock the decider network so the pick behavior is atomic.
Close the gripper for .5 seconds.
Lift for .25 seconds.
Mark the block as being in the gripper.
Unlock the decider network.
Much of this behavior is simply a timed sequence. If for any reason it’s unsuccessful, the decider network will be reactive to that at a higher level and recover. So we can model this behavior as simply a blind behavior that executes at the right time. It records its belief (that the block is in the gripper), but the context will continue to monitor whether that’s true.
The PlaceBlockRd is another atomic sequential state machine similar to the pick state machine:
class PlaceBlockRd(DfStateMachineDecider, DfRldsNode):
def __init__(self):
# This behavior uses the locking feature of the decision framework to run a state machine
# sequence as an atomic unit.
super().__init__(
DfStateSequence(
[
DfSetLockState(set_locked_to=True, decider=self),
DfTimedDeciderState(DfOpenGripper(), activity_duration=0.5),
DfTimedDeciderState(Lift(0.15), activity_duration=0.35),
DfWriteContextState(lambda ctx: ctx.clear_gripper()),
DfWriteContextState(set_top_block_aligned),
DfTimedDeciderState(DfCloseGripper(), activity_duration=0.25),
DfSetLockState(set_locked_to=False, decider=self),
]
)
)
This state sequence includes opening, lifting, writing logical state, and closing the gripper. Note
that set_top_block_aligned marks an is_aligned flag in the block. In this demo we don’t do
anything with that flag, but in a real-world system implementation, we would likely have two
behaviors, a place behavior, then an align behavior. Placement might be inaccurate, so on initial
placement the is_aligned flag is False. Then the decider would see that and run a pinch
alignment behavior which results in is_aligned being set to True. This a good example of
logical state that’s unobservable. Perception modules might not be accurate enough to fully detect
whether the block is misaligned, but pinching the block we know will align it to higher precision.
So we can run that behavior, and simply mark that it’s been run.
In this example, keep the is_aligned logical state in there, but for brevity we don’t implement
the pinch alignment behavior.
Logical state context
All of these behaviors are supported by the logical state information extracted by the
BuildTowerContext. The easiest way to understand what information the context extracts as
logical state is to look at the collection of logical state monitors it uses:
class BuildTowerContext(DfContext):
...
def __init__(self, robot, tower_position):
...
self.monitors = [
BuildTowerContext.monitor_perception,
BuildTowerContext.monitor_block_tower,
BuildTowerContext.monitor_gripper_has_block,
BuildTowerContext.monitor_suppression_requirements,
BuildTowerContext.monitor_diagnostics,
]
In order, the set of monitors are:
Monitor perception: Periodically sync measured block transforms to the belief blocks. Syncing is suppressed when the block is in the end-effector and the measured transform is within a radius of the belief. Since the block is moving, we expect the belief to be more accurate during this period than perception, but it’s still reactive to the block falling from the gripper.
Monitor block tower: Based on the positions of the blocks, it infers what the current state of the block tower is and populates the
block_towerdata structure appropriately. Decider nodes can query the state of the block tower using that data structure and it will always reflect the current state.Monitor gripper has block: Monitors whether there’s a block in the gripper. There’s an interaction between this monitor and the pick behavior. The pick behavior will seed the belief that there’s a block in the gripper since that was the intent, and this monitor simply verifies that it’s true.
Monitor suppression requirements: Generally, collision avoidance is active between the robot and the blocks (expecially important to avoid knocking the tower down). But the robot needs to interact with the blocks when picking and placing. This monitor automatically suppresses collisions when interaction with blocks is expected.
Monitor diagnostics: Prints some information about the logical state at a readable (throttled) rate.
The information collected by the logical state monitors is everything needed for the decider network to make robust reactive decisions.