Carbonite Crash Reporter#
Overview#
The crash reporter is intended to catch and handle exceptions and signals that are produced at runtime
by any app that loads it. On startup, if configured to do so, the crash reporter will install itself
in the background and wait for an unhandled exception or signal to occur. There is no performance
overhead for this to occur and for the most part the crash reporter plugin just sits idle until a
crash actually occurs. The only exception to this is that it will monitor changes to the /crashreporter/
branch in the settings registry (managed by the carb::settings::ISettings interface if present).
The crash reporter plugin does not have any other dependent plugins. It will however make use of the
carb::settings::ISettings interface if it is loaded in the process at the time that the crash
reporter plugin is loaded. Any changes to the /crashreporter/ settings branch will be monitored
by the plugin and will have the possibility to change its configuration at runtime. See below in
Configuration Options for more information in the specific settings that can be used to
control its behavior.
Note that if an implementation of the carb::settings::ISettings interface is not available
before the crash reporter plugin is loaded, the crash reporter will not be able to reconfigure itself
automatically at runtime. In this case, the crash reporter will only use its default configuration
(ie: no crash report uploads, write reports to the current working directory). If the
carb::settings::ISettings interface becomes available at a later time, the crash reporter
will automatically enable its configuration system. When this occurs, any configuration changes
listed in the settings registry will be loaded and acted on immediately.
The implementation of the crash reporter plugin that is being referred to here is based on the Google
Breakpad project. The specific plugin is called carb.crashreporter-breakpad.plugin.
Common Crash Reporter Terms#
“Crash Report”: A crash report is a collection of files, metadata, and process state that describes a single crash event. This collection may be compressed into a zip file or stored as a loose files. The crash report may be stored locally or be uploaded to a crash report processing system for later analysis.
“Crash Dump”: This is a file included in a crash report that contains the process state at the time of a crash. This typically contains enough information to do a post-mortem analysis on the state of the crashing portion of the process, but does not always contain the complete state of the process. This file is often one of the largest components in a crash report.
“Crash Log”: The log file related to the crashing process. This can help a crash investigator determine what the crashing process may have been doing near the time of the crash or perhaps even contain a reason for the crash. This log file is not automatically included in a crash report. Since this log may contain either confidential information or personally identifiable information (ie: file names and paths, user names, etc), care must be taken when deciding to include a log file in a crash report.
“Metadata”: Each application can include its own custom data points with any crash report. These are referred to as metadata values. These can be set by the application at any time before a crash occurs. All registered metadata values will be included with a crash report when and if it is generated. See Crash Handling and Metadata for more info on how to add metadata. Metadata comes in two flavors - static and volatile. A static metadata value is not expected to change during the lifetime of the process (or change rarely). For example, the application’s product name and version would be static metadata. See below for a description of volatile metadata.
“Volatile Metadata”: A volatile metadata value is one that changes frequently throughout the lifetime of the process. For example, the amount of system memory used at crash time would be considered volatile. Adding such a value as static metadata would potentially be very expensive at runtime. A volatile metadata value instead registers a callback function with the crash reporter. When and if a crash occurs, this callback is called so that the crash reporter can collect the most recent value of the metadata.
“Extra Files”: A crash report can contain zero or more custom extra files as well. This is left up to the application to decide which files would be most interesting to collect at crash time. It is the responsibility of the application to ensure that the files being collected do not contain any confidential or personally identifiable information.
Setting Up the Crash Reporter#
When the Carbonite framework is initialized and configured, by default an attempt will be made to
find and load an implementation of the carb.crashreporter-*.plugin plugin. This normally occurs
after the initial set of plugins has been loaded, including the plugin that implements the
carb::settings::ISettings interface. If a crash reporter implementation plugin is
successfully loaded, it will be ‘registered’ by the Carbonite framework using a call to
carb::crashreporter::registerCrashReporterForClient(). This will ensure the crash reporter’s
main interface carb::crashreporter::ICrashReporter is loaded and available to all modules.
The default behavior of loading the crash reporter plugin can be overridden using the flag
carb::StartupFrameworkDesc::disableCrashReporter when starting the framework.
If this is set to true, the search, load, and registration for the plugin will be skipped.
In that case, it will be up to the host app to explicitly load and register its own crash reporter if
its services are desired.
Once loaded and registered, the Carbonite framework will make an attempt to upload old crash report
files if the /app/uploadDumpsOnStartup setting is true (this is also the default value).
Note that this behavior can also be disabled at the crash reporter level using the setting
/crashreporter/skipOldDumpUpload. This upload process will happen asynchronously in the background
and will not affect the functionality of other tasks. If the process tries to exit early however,
this background uploading could cause the exit of the process to be delayed until the current upload
finishes (if any). There is not currently any way to cancel an upload that is in progress.
Most host apps will not need to interact with the crash reporter very much after this point. The only functionality that may be useful for a host app is to provide the crash reporter with various bits of metadata about the process throughout its lifetime. Providing this metadata is discussed below in Crash Handling and Metadata.
Configuring the Crash Reporter#
See Configuration Options for a full listing of available configuration settings.
Once the crash reporter plugin has been loaded, it needs to be configured properly before any crash
reports can be sent anywhere. Crash reports will always be generated locally if the crash reporter
is loaded and enabled (with the /crashreporter/enabled setting). When the crash reporter is
disabled, the operating system’s default crash handling will be used instead.
To enable uploads of generated crash reports, the following conditions must be met:
The
/crashreporter/enabledsetting must be set totrue.The
/crashreporter/urlsetting must be set the URL to send the generated crash report to. The default Nvidia crash reporting system’s URL is https://services.nvidia.com/submit.The
/crashreporter/productsetting must be set to the name of the product that crashed. The URL that the crash report is being sent to may have other restrictions on the allowed product names as well. For example, the URL may reject crash reports that arrive with unknown product names.The
/crashreporter/versionsetting must be set to the version information of the crashing app. This value may not be empty, but is also not processed for any purposes except crash categorization and display to developers.Either the
/privacy/performancesetting must be set totrueor the/crashreporter/devOnlyOverridePrivacyAndForceUploadsetting must be set totrue. The former is always preferred but should never be set explicitly in an app’s config file. This is a user consent setting and should only ever be set through explicit user choice. It should also never be overridden with/crashreporter/devOnlyOverridePrivacyAndForceUploadexcept for internal investigations.
Only the main process (ie: kit-kernel) should ever configure the crash reporter. This can
either be done in startup config files, on the command line, or programmatically. A plugin or
extension should never change this base configuration of the crash reporter. Plugins and extensions
may however add crash report metadata and extra files (described below).
Once the crash reporter has been configured in this way, each new crash report that is generated will be attempted to be uploaded to the given URL. Should the upload fail, another crash occurs during the upload (the process is possibly unstable after a crash), or the user terminates the process during the upload, an attempt to upload it again will be made the next time any Carbonite based app starts up using the same crash dump folder. By default, up to 10 attempts will be made to upload any given crash report. Each attempt will be made on a separate run of a Carbonite app. If all attempts fail, the crash report will simply be deleted from the local directory.
After a crash report is successfully uploaded, it will be deleted from the local dump directory
along with its metadata file. If the crash report files should remain even after a successful upload,
the /crashreporter/preserveDump setting should be set to true. This option should really
only be used for debugging purposes. Note that if a crash report is preserved and it has already
been successfully uploaded, another attempt to upload it will not be made.
By default, the crash reports dump directory will be the app’s current working directory. This
can be changed using the /crashreporter/dumpDir setting. Any relative or absolute path may
be used here. The named directory must exist before any crash occurs.
Compressed Crash Reports#
The carb.crashreporter-breakpad.plugin implementation includes support for creating zip
compressed crash reports. Typically a crash dump file will compress down to ~10% of its original
size which can save a lot of time and bandwidth usage uploading the crash reports. Log files
typically compress very well too. This feature is enabled with the /crashreporter/compressDumpFiles
setting. When set to true, a zip compressed crash report will be used instead.
The crash report management system that NVIDIA provides does support accepting zipped crash report
files. When enabled, all files that are to be included with the crash report will be included in a
single zip archive and sent along with the crash metadata. In this case, the crash report’s file
will have the extension .dmp.zip and its metadata file will have the extension .dmp.zip.toml.
This feature is still in the beta stage, but is being used exclusively by some Carbonite based apps both internally and publicly.
As of Carbonite 208.0, the /crashreporter/compressDumpFiles setting now defaults to true.
Configuring the Crash Reporter to Send to Sentry#
The crash reporter can be configured to send its crash reports to a Sentry instance. The Sentry instance must be configured to accept minidumps first. Sentry has a special endpoint they call the ‘minidump endpoint URL’ that can be configured to be able to accept crash reports from Kit and Carbonite based apps. This type of crash reporting will only accept crash reports from the C/C++ side of the app. It will not be used by Kit to report on Python crashes/excptions or from any other scripting language.
To configure this on the Kit side, a couple changes are needed:
Change the
/crashreporter/urlsetting to point to the Sentry instance’s minidump endpoint URL.Disable compressed crash reports by setting
/crashreporter/compressDumpFilestofalse. Sentry does document that it supports compressed crash reports, but it expects the files and form in a different format than the crash reporter delivers.
In order for Sentry to be able to accept and process minidumps, it must be made aware of the symbols for the app. Sentry hosts its own symbol server that must be configured and populated with symbols for each module that could be involved in a crash callstack. The documentation on Sentry’s symbols server can help with this process. It is the developers’ responsibility to ensure Sentry’s symbol server has enough information to effectively process a crash dump. This functionality is not provided on the app side by the crash reporter.
Note
It is possible that Sentry may not be able to fully process a crash callstack if symbol files involved in a given stack frame are missing. This can especially occur when the function on the stack frame was linked with frame pointer optimization (FPO) enabled. When such a problem occurs, some debuggers will start trying to walk the stack memory one qword at a time checking if it can be resolved as a symbol. In those cases, the callstack will either be truncated or could contain invalid stack frames after that point. It is the developer’s responsibility to be able to verify the validity of the crash callstack and look out for these issues before making debugging decisions.
Warning
While this functionality may work with Sentry, it may not be officially supported by Carbonite or Sentry. This is just an outline of how the crash reporter could be configured to deliver its crash reports to Sentry.
Crash Handling and Metadata#
When a crash does occur in the app, the crash reporter will catch it. Upon catching a crash, the crash reporter plugin will create a crash dump file and collect metadata from the running app. The format of the crash dump file will differ depending on the platform.
On Windows, a minidump file compatible with Microsoft Visual Studio will be created. On Linux,
a proprietary crash dump file will be created. This file is compatible with Microsoft minidump
files, but will not necessarily contain information that Visual Studio can fully understand.
This Linux crash dump file can be converted to a stripped-down Linux core dump file with the use of a
helper tool from the Breakpad library (the tool is utils/minidump-2-core in the separately-distributed
Google Breakpad packman package). A minidump or core
dump file contains some portions of the state of the process at the time it crashed. This state
includes the list of running threads, each of their CPU register states, portions of their stack
memory, a list of loaded modules, and some selected memory blocks that were referenced on the
various thread stacks. From this crash state information some investigation can successfully be
done into what may have caused the crash. The dump files do not contain all of the process’ state
information by default since that could be several gigabytes of data.
The metadata for the crash will be collected from multiple sources both at crash time and as the program runs. The metadata is simply a set of key-value pairs specified by the host app. The metadata values may be any string, integer, floating point, or boolean value (arrays of these values are not currently supported) and are collected from these sources:
Any value specified in a call to
carb::crashreporter::addCrashMetadata(). This is just a helper wrapper for adding metadata values through the/crashreporter/data/settings branch. This is the preferred method of adding constant metadata values.Any key/value pairs written to the
/crashreporter/data/branch of the settings registry. This registers a constant metadata key-value pair and is best used for values that do not change at all or do not change frequently throughout the app’s lifetime. These metadata values are collected and stored immediately. This method of adding metadata can be used on the command line or in a config file for example if the information is known at launch time.Any ‘volatile’ metadata values specified with
carb::crashreporter::ICrashReporter::addVolatileMetadata(). This registers a value to be collected at crash time through a callback function. This type of metadata is intended to be used for values that change frequently and would be too expensive to update immediately every time they change. The only value that is important is the last value at the time of a crash. For example, this is used internally to collect the process uptime and memory usage information at the time of a crash.
Regardless of how a metadata value is added, its key name will be always sanitized to only contain characters that are friendly to database key names. This sanitization will involve replacing most symbol characters with an underscore (‘_’). All key names should only contain ASCII characters as well. Metadata values may contain any UTF-8 codepoints however.
Python Tracebacks#
The crash reporter has the ability to run a utility when a crash is detected that will inspect the Python interpreter running in the process and produce a Python traceback of all Python threads. By default this utility is py-spy. The utility’s binary must be in the same directory as the crash reporter, as the application binary, or in the working directory of the process at configuration time.
For this process to work correctly, the Python library must be an official distribution, or it must have symbols packaged along with it.
Several configuration keys (containing pythonTraceback) can configure how the process runs.
The metadata key PythonTracebackStatus will record the outcome of gathering the Python traceback. The Python
traceback is uploaded as a separate text file. The process must return an exit code of 0 to be considered successful.
User Story#
The crash reporter can also run a separate process in order to gather information from the user. This is known as the “user story”–the user’s telling of what they were doing when the crash occurred. This may provide some hints necessary to reproduce and diagnose the problem.
Several configuration keys (containing userStory) can configure how the process runs.
The metadata key UserStoryStatus will record the outcome of gathering the user story.
By default, this is crashreport.gui, a small and simple GUI application maintained by Carbonite:
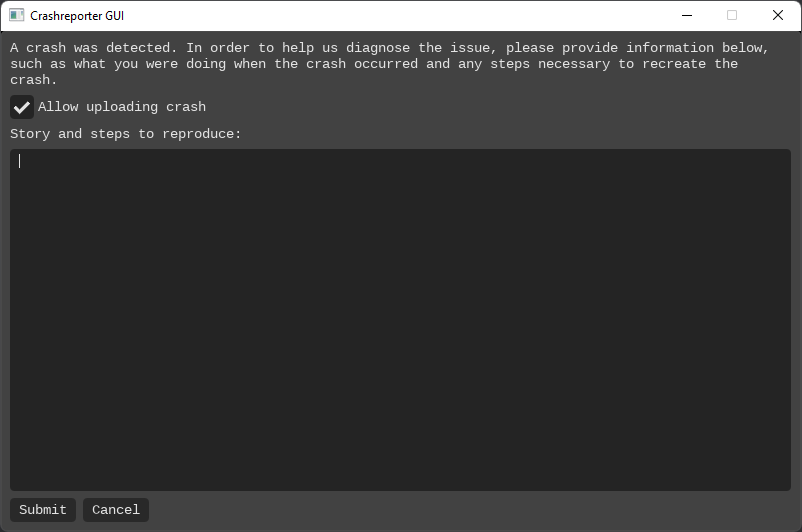
The checkbox will be auto-populated based on whether crash dumps are allowed to be uploaded (both configuration and privacy settings affect this). However, if the user submits a crash report, that acts as a privacy consent to send a report. If the user cancels, the crash is deleted (ignoring configuration to persist crashes). If the checkbox is not checked, the ‘Submit’ button is disabled and cannot be pressed.
Both pressing the ‘Cancel’ button, or pressing the ‘Submit’ button with the text box empty will cause a popup message to
be displayed for the user to confirm the action. These can be suppressed by adding --/app/window/confirmOnCancel=1 or
--/app/window/confirmOnEmptyRepro=1 respectively to the arguments in the /crashreporter/userStoryArgs configuration keys
(though the default arguments from that key must be part of your redefinition).
The binary is expected to log the user story to stdout and produce an exit code of 0 to submit the crash, or
1 to cancel and delete the crash. Any other exit code (or a timeout) will report an error to the UserStoryStatus
metadata field and proceed as if the user story binary was not run (i.e. uploading based on current configuration).
The tool requires --/app/crashId=<crash ID> to be passed on the command line (with <crash ID> as the current crash ID)
in order to fully start, otherwise a message is displayed that the application is not intended to be run manually.
Adding Extra Files to a Crash Report#
By default a crash report is sent with just a crash dump file and a set of metadata key/value pairs. If necessary, extra files can be added to the crash report as well. This could include log files, data files, screenshots, etc. However, when adding extra files to a crash report, care must be taken to ensure that private data is not included. This is left up to the system adding the extra files to verify. Private data includes both personal information of users and potential intellectual property information. For example, this type of information is highly likely to unintentionally exist in log files in messages containing file paths.
To add an extra file to a crash report, one of the following methods may be used:
Call
carb::crashreporter::addExtraCrashFile()to add the new file path. This may be a relative or absolute path (though if a relative path is used, the current working directory for the process may not change). This is the preferred method for adding a new file.Add a new key and value to the
/crashreporter/files/branch of the settings registry. This can be done in a config file or on the command line if the path to the file is known at the time. This can also be done programmatically if necessary.
When extra files are included with the crash report, they will all be uploaded in the same POST request as the main crash dump file and metadata. These extra files will be included whether the crash report has been compressed or not.
Crash Report Files#
When a crash occurs, several new files may be created in the specified ‘dump directory’ (specified with
the /crashreporter/dumpDir setting, defaults to the current working directory). Most of these files
will be uploaded with the crash report if an upload URL is provided. If compressed crash reports are
enabled (specified with the /crashreporter/compressDumpFiles setting, defaults to true as of
Carbonite 208.0), most of these created crash report files will be added to the .zip archive that is
created for the crash report.
The following files may be created by the crash reporter when a crash occurs:
<dumpID>.dmpand<dumpID>.dmp.toml: When compressed crash reports are disabled, these two files will be created as the main content of the crash report.The
.dmpfile is a binary file that contains information about the state of the process when it crashed. This can be later analyzed to get more information about the crash.The
.dmp.tomlfile is a text file containing all of the metadata values and the file list that was included with the crash report. The file list will include these two files plus any extra files that may have been added to the crash report dynamically.
<dumpID>.dmp.zipand<dumpID>.dmp.zip.toml: When compressed crash reports are enabled, these two files will be created as the main content of the crash report.The
.dmp.zipfile is a .zip archive that contains all of the files that will be uploaded with the crash report. This includes the matching metadata file and the.dmpfile described above. This can be later analyzed to get more information about the crash.The
.dmp.zip.tomlfile is a text file containing all of the metadata values and the file list that was included with the crash report. The file list will in this case will only include the single.dmp.ziparchive file that will be uploaded. All other files will be included inside the .zip archive file itself.
<dumpID>.py.txt: When the py-spy helper binary is shipped with an app, this file will be created at crash time. This will contain a summary of all the Python stacks that are running at the time of the crash. This can be used to diagnose Python errors and whether they may have contributed to the crash. This file will be automatically included with the crash report.crash_<timestamp>.txt: This is a text file that will contain a summary of the crash that occurred. This summary will include the metadata values, file list, and a stack trace of the crashing thread. The stack trace will often not be symbolicated. This file will not be automatically included with the crash report and will not be deleted if the crash report is successfully uploaded. Stack frames that could not be symbolicated will have a[low-confidence]suffix as an indication that any name of the function should be not be treated confidently.
Additional files may be included in the crash report as well if they are dynamically added with one of the methods listed in Adding Extra Files to a Crash Report. The contents and purpose of these extra files is not known to the crash reporter though and the files will simply be included in the crash report as they are when the crash occurs. If compressed crash reports are enabled, these extra files will be included in the .zip archive. Otherwise they will remain in their original locations.
If a crash report is successfully uploaded to the specified URL, the default behavior is to delete the
.dmp, .dmp.zip, .dmp.toml, and .dmp.zip.toml files. These files can be preserved after
the upload if the /crashreporter/preserveDump setting is enabled.
Loading a Crash Dump to Investigate#
On Windows, a crash dump file can be opened by dragging it into Visual Studio then selecting “Debug with native only” on the right hand side of the window. This will attempt to load the state of the process at the time of the crash and search available symbol servers for symbols and code to the modules that were loaded at the time of the crash. The specific symbol and source servers that are needed to collect this information depend on the specific project being debugged.
Once loaded, many of the features of the Visual Studio debugger will be available. Note that symbols and source code may or may not be available for every module depending on your access to such resources. Some restrictions in this mode are that you won’t be able to step through code or change the instruction pointer’s position. Also, global data may not be available depending on the contents of the crash dump file.
If a particular crash is repeatable, the /crashreporter/dumpFlags setting can be used to collect more
information in the crash dump file that is created. Note though that some of the flags that are available
can make the crash dump very large. On Windows, the following dump flags are available:
Normal: only capture enough information for basic stack traces of each thread.WithDataSegs: include the memory for the data sections of each module. This can make the dump file very large because it will include the global memory space for each loaded module.WithFullMemory: include all of the process’ mapped memory in the dump file. This can cause the dump file to become very large. This will however result in the most debuggable dump file in the end.WithHandleData: includes all of the OS level information about open handles in the process.FilterMemory: attempts to filter out blocks of memory that are not strictly needed to generate a stack trace for any given thread.ScanMemory: attempts to scan stack memory for values that may be pointers to interesting memory blocks to include in the dump file. This can result in a larger dump file if a lot of large blocks are included as a result of the scan.WithUnloadedModules: attempts to include a list of modules that had been recently unloaded by the process.WithIndirectlyReferencedMemory: includes blocks of memory that are referenced on the stack of each thread. This can result in a significantly larger dump file.FilterModulePaths: filters out module paths that may include user names or other user related directories. This can avoid potential issues with personally identifying information (PII), but might result in some module information not being found while loading the dump file.WithProcessThreadData: includes full process and thread information from the operating system.WithPrivateReadWriteMemory: searches the process’s virtual memory space and includes all pages that have thePAGE_READWRITEprotection.WithoutOptionalData: attempts to remove memory blocks that may be specific to the user or is not strictly necessary to create a usable dump file. This does not guarantee that the dump file will be devoid of PII, just reduces the possibility of it.WithFullMemoryInfo: includes information about the various memory regions in the process. This is simply the page allocation, protections, and state information, not the data in those memory regions itself.WithThreadInfo: includes full thread state information. This includes thread context and stack memory. Depending on the number of threads and amount of stack space used, this can make the dump file larger.WithCodeSegs: includes code segments from each module. Depending on the number and size of modules loaded, this can make the dump file much larger.WithoutAuxiliaryState: disables the automatic collection of some extra memory blocks.WithFullAuxiliaryState: includes memory and state from auxilary data providers. This can cause the dump file to become much larger.WithPrivateWriteCopyMemory: includes memory blocks that have thePAGE_WRITECOPYprotection. This can make the dump file larger if a lot of large blocks exist.IgnoreInaccessibleMemory: if theWithFullMemoryflag is also used, this prevents the dump file generation from failing if an inaccessible region of memory is encountered. The unreadable pages will not be included in the dump file.WithTokenInformation: includes security token information in the dump file.WithModuleHeaders: includes the headers from each loaded module.FilterTriage: adds filter triage related data (not clear exactly what this adds).WithAvxXStateContext: includes the AVX state context for each thread (x86_64 only).WithIptTrace: includes additional Intel Processor Trace information in the dump file.
On Linux, the process for loading a crash dump file is not entirely defined yet. Depending on how in depth
the investigation needs to be, there are two currently known methods. Both require some tools from the
Breakpad SDK. The following methods are suggested but not officially supported yet:
use the
minidump-2-coretool fromBreakpadto convert the crash dump file to a standard Linux core dump file. Note that by default this tool will output the result tostdoutwhich can break some terminals. Instead the output should always be redirected to a file. This file can then be opened with GDB using the commandgdb <executable> --core <core_file>. GDB may also need to be pointed to the various symbol files for the process. Please see the manual for GDB on how to find and load symbol files if needed. Carbonite also provides agdb-syms.pyPython script for GDB that will attempt to download symbols from the NVIDIA Omniverse symbol server.use the
minidump-stackwalktool to attempt to retrieve a stack backtrace for each thread listed in the crash dump file. This will produce a lot of output so it is best to redirect it to a file. This can provide some basic information about where the crash occurred and can give at least an idea of a starting point for an investigation.
The current crash report management system (called OmniCrashes) usually does a good job of extracting crash information for all platforms and displays it. This is an internal crash reporting system however and cannot be accessed publicly. It is however a deployable product for customers who need to run their own instance of OmniCrashes.
Uploading Crash Reports#
NVIDIA provides a default URL to send crash reports to - https://services.nvidia.com/submit. At this
location, crash dumps and metadata will be accepted via HTTP POST commands. The expected format of the
POST is a multipart form that provides key/value pairs for each of the metadata items followed by the
binary data for the crash dump file itself, followed by any additional files to be included with the
crash report upload. The crash report files are processed at this location and stored for later investigation.
This default location can always be overridden by using the /crashreporter/url setting. The new URL
will still be expected to accept POSTed forms in the same format.
Once a crash report is created locally on a machine, the default behavior (if enabled) is to attempt
to upload the crash dump and its associated metadata to the current upload URL. There are multiple
settings that can affect how and if the crash report upload will occur. See Configuring the Crash Reporter
and Configuration Options for more information on those specific settings. The upload
is performed synchronously in the crashing thread. Once finished and if successful, the crash dump
file and its metadata may be deleted locally (depending on the /crashreporter/preserveDump setting).
If the upload is not successful for any reason, the crash dump and metadata files will be left locally
to retry again later. By default, up to 10 attempts will be made for each crash report.
Should the upload fail for any reason on the first attempt (ie: in the crashing process), an attempt
to upload it again will be made the next time the app is run. The original upload could fail for
many reasons including network connection issues, another crash occurred while trying to do the
original upload, or even that the server side rejected the upload. When retrying an upload in future
runs of the app, old crash dump files will be uploaded sequentially with their original metadata.
Should a retry also fail, a counter in the metadata will be incremented. If an upload attempt
fails too many times (see /crashreporter/retryCount below), the crash dump file and its metadata
file will be deleted anyway. If a crash report is successfully uploaded during a retry and the
/crashreporter/preserveDump setting is set to true, the crash report’s metadata will be
modified to reflect that change so that another upload attempt is not made.
Debugging Crashes#
Sometimes it is necessary to intentionally cause a crash multiple times in order to debug or triage it properly. For example, this might be done in order to try to determine crash reproduction steps. If the build it is being tested on has the crash reporter properly configured, this could result in a lot of extra crash dumps being uploaded and a lot of unnecessary work and noise being generated (ie: crash notifications, emails, extra similar crashes being reported, etc). In cases like this it may be desirable to either not upload the crash report at all or at least mark the new crash(es) as “being debugged”.
This can be done in one of a few ways:
Add a new metadata value to the crash report indicating that it is an intentional debugging step. This can be done for example with the command line option or config setting
--/crashreporter/data/debuggingCrash=1. This is the preferred metadata key to use to indicate that crash debugging or triage is in progress.Disable crash reporter uploads for the app build while testing. The easiest way to do this is to simply remove the upload URL setting. This can be done with a command line option such as
--/crashreporter/url="". This should override any settings stored in config files.If the crash report itself is not interesting during debugging, the crash reporter plugin itself could just be disabled. This can be done with
--/crashreporter/enabled=false.
For situations where a command line option is difficult or impossible, there are also some environment variables that can be used to override certain aspects of the crash reporter’s behavior. Each of these environment variables has the same value requirements as the setting they override (ie: a boolean value is expected to be one of ‘0’, ‘1’, ‘n’, ‘N’, ‘y’, ‘Y’, ‘f’, ‘F’, ‘t’, or ‘T’). The environment variables and the settings they override are:
OMNI_CRASHREPORTER_URLwill override the value of the/crashreporter/urlsetting.OMNI_CRASHREPORTER_ENABLEDwill override the value of the/crashreporter/enabledsetting.OMNI_CRASHREPORTER_SKIPOLDDUMPUPLOADwill override the value of the/crashreporter/skipOldDumpUploadsetting.OMNI_CRASHREPORTER_PRESERVEDUMPwill override the value of the/crashreporter/preserveDumpsetting.OMNI_CRASHREPORTER_DEBUGGERATTACHTIMEOUTMSwill override the value of the/crashreporter/debuggerAttachTimeoutMssetting.OMNI_CRASHREPORTER_CRASHREPORTBASEURLwill override the value of the/crashreporter/crashReportBaseUrlsetting.
It is highly recommended that these environment variable overrides only ever be used in situations where
they are the only option. They should also only be used in the most direct way possible to ensure that
they do not unintentionally affect the system globally, but only the single intended run of the Carbonite
based app. Especially on Windows, environment variables will remain persistent in the terminal they are
set in. On Linux, if possible new environment variables should be added to the start of the command line
that launches the process being tested (ie: OMNI_CRASHREPORTER_ENABLED=0 ./kit [<other_arguments>]).
Public Interfaces and Utilities#
Instead of being configured programmatically through an interface, all of the crash reporter’s
configuration goes through the carb::settings::ISettings settings registry. Upon load of
the plugin, the crash reporter plugin will start monitoring for changes in the /crashreporter/ branch
of the settings registry. As soon as any value in that branch changes, the crash reporter will be
synchronously notified and will update its configuration.
While the crash reporter is intended to be a service that largely works on its own, there are still Some
operations a host app can perform on it. These are outlined in the documentation for the
carb::crashreporter::ICrashReporter interface. These operations include starting a
task of trying to upload old crash report files, registering callback functions for any time a crash report
upload completes, resolving addresses to symbols (for debug purposes only), and adding volatile
metadata for the process.
There are also some utility helper functions in the carb::crashreporter namespace that
can simplify some operations such as adding new static metadata values or adding extra files to the
crash report. The only set of functions that should be directly called from there are the
carb::crashreporter::addCrashMetaData(), carb::crashreporter::addExtraCrashFile(),
and carb::crashreporter::isExtraCrashFileKeyUsed().
Configuration Options#
The Carbonite crash reporter (carb.crashreporter-breakpad.plugin) has several configuration
options that can be used to control its behavior. These are specified either in an app’s config
file or on the command line. The following settings keys are defined:
"/crashreporter/url": The URL to use when uploading crash report files. By default this will be an empty string. The URL is expected to be able to accept multipart form messages being posted to it. Many omniverse apps will be automatically configured to use the default upload URL of https://services.nvidia.com/submit using this setting. This can then be overridden on the command line or in a config file if needed. This setting is required in order for any uploads of crash reports to occur. This setting can be overridden with the environment variableOMNI_CRASHREPORTER_URL."/crashreporter/product": Sets the name of the product for which crash reports will be generated. This setting is required in order for any uploads of crash reports to occur. This becomes the product name that is included with the crash report’s metadata. Without this metadata value set, the NVIDIA URL will reject the report files. This may be any string value, but should be descriptive enough of the name of the app that it can be distinguished from crash reports for other products. This defaults to an empty string."/crashreporter/version": Sets the version information for the app. This setting is required in order for any uploads of crash reports to occur. This becomes the version information that is included with the crash report’s metadata. Without this metadata value set, the NVIDIA URL will reject the report files. This may be any string value, but should be descriptive enough of the version information of the crashing app that an investigation can be done on it. This defaults to an empty string."/crashreporter/dumpDir": The full path to the location to write crash dump and metadata files to on the local machine. This will also be the location that old crash reports are uploaded from (if they exist) on subsequent runs of the app. This directory must already exist and will not be created by the crash reporter itself. By default this is the current working directory."/crashreporter/enabled": Sets whether the crash reporter is enabled or not. By default, the crash reporter will be enabled on load of the plugin. This setting can change at any point during the process’ lifetime and it will be acted on immediately by the crash reporter. When the crash reporter is disabled, its exception/signal catching hooks will be removed. The plugin will remain loaded and functional, but no action will be taken if a crash does occur. When the crash reporter is enabled, the exception/signal catching hooks will be installed again. This defaults totrue."/crashreporter/devOnlyOverridePrivacyAndForceUpload": Sets whether crash report files should be uploaded after they are created. This can be used to override the user’sperformanceconsent setting for the purposes of uploading a crash report if needed. If this isfalse, the user’sperformanceconsent setting will control whether uploads are attempted. Note that this setting is effectively ignored if no upload URL has been set in/crashreporter/url. This defaults tofalse. This setting should _never_ be used in a released product. This is only intended for local debugging."/crashreporter/skipOldDumpUpload": Indicates whether attempts to upload old crash report files should be skipped. This is useful for situations such as test apps or launching child instances of an app so that they don’t potentially end up blocking during shutdown due to an upload in progress. This defaults tofalse. This setting can be overridden with the environment variableOMNI_CRASHREPORTER_SKIPOLDDUMPUPLOAD."/crashreporter/log": When enabled, this indicates whether a stack trace of the crashing thread should be written out to the app log. This will attempt to resolve the symbols on the callstack as best it can with the debugging information that is available. This defaults totrue."/crashreporter/preserveDump": When enabled, this indicates that crash report files that were successfully uploaded should not be deleted. This is useful in situations such as CI/CD so that any crash report files from a crashed process can be stored as job artifacts. This defaults tofalse. This setting can be overridden with the environment variableOMNI_CRASHREPORTER_PRESERVEDUMP."/crashreporter/data/": Settings branch that may contain zero or more crash metadata key/value pairs. Any non-array setting created under this settings branch will be captured as metadata values for the process. These metadata values can be added at any point during runtime up until an actual crash occurs. These settings may also be provided on the command line or in config files if the metadata value is known at the time. A new metadata value can be added programmatically at runtime using thecarb::crashreporter::addCrashMetadata()helper function. This defaults to an empty settings branch.Note
Care must be taken to ensure that no user or third party intellectual property information is included in a metadata value. This is always the responsibility of the app, plugin, extension, script, config file author, etc to ensure. It is acceptable to include user information for internal test runs, but this functionality or configuration may not be exposed to public end users.
"/crashreporter/files/": Settings branch that may contain zero or more extra files that should be included in crash reports. Each key/value pair found in this settings branch will identify a new file to be included. The key is expected to be a descriptor of why the file is included. The value is expected to be the relative or absolute path to the file to be included. If a relative path is used, it is up to the app to guarantee that the current working directory that path is relative to will not be modified between when it is added and when a crash report is generated. It is highly suggested that absolute paths always be given to avoid this. Settings in this branch may be added, removed, or modified at any point during runtime up until an actual crash occurs. These settings may also be provided on the command line or in config files if the file name and path is known ahead of time (regardless of whether the file exists at the time). Any listed files that do not exist or are inaccessible at crash time will be silently ignored. A new extra file setting can be added programmatically using thecarb::crashreporter::addExtraCrashFile()helper function. This default to an empty settings branch.Note
Care must be taken to ensure that no user or third party intellectual property information is included in any extra file that is sent with a crash report. This is always the responsibility of the app, plugin, extension, script, config file author, etc to ensure. It is acceptable to include user information for internal test runs, but this functionality or configuration may not be exposed to public end users.
"/crashreporter/metadataToEmit": Array setting to specify which metadata values should also be emitted as telemetry events. Each entry in the array is expected to be a regular expression describing the pattern to try to match each new metadata value to. Note that only new or modified metadata values will be reported as telemetry events once a specified pattern is added to the array. To capture all new metadata key/value pairs, these patterns should be specified either in a config file or on the command line. Note that this will not be able to capture any of the metadata values that are internally generated by the crash reporter since most of these internal metadata values are only given values at crash time. The patterns in this array may be changed at any point during runtime. However, if a pattern changes only new or modified metadata values after that point will be emitted as telemetry events. Only a single telemetry event will be emitted for each new or modified metadata value. If a piece of metadata is set again to its current value, no new event will be emitted. This defaults to an empty array."/crashreporter/uploadTimeoutMs": Windows only. Provides a timeout in milliseconds that, when exceeded, will consider the upload as failed. This does not limit the actual amount of time that the upload takes due to a bug inwininet. Typically this value does not need to be changed. This defaults to 7,200,000ms (2 hours)."/crashreporter/debuggerAttachTimeoutMs": Determines the time in milliseconds to wait for a debugger to attach after a crash occurs. If this is a non-zero value, the crash report processing and upload will proceed once a debugger successfully attaches to the process or the given timeout expires. This is useful when trying to debug post-crash functionality since some debuggers don’t let the original exception go completely unhandled to the point where the crash reporter is allowed to handle it (ie: if attached before the crash). This setting defaults to 0ms meaning the wait is disabled. This setting can be overridden with the environment variableOMNI_CRASHREPORTER_DEBUGGERATTACHTIMEOUTMS."/crashreporter/dumpFlags": Flags to control which data is written to the minidump file (on Windows). These can either be specified as a single hex value for all the flags to use (assuming the user knows what they are doing), or with MiniDump* flag names separated by comma (‘,’), colon (‘:’), bar (‘|’), or whitespace. There should be no whitespace between flags when specified on the command line. The ‘MiniDump’ prefix on each flag name may be omitted if desired. This defaults to an empty string (ie: no extra flags). The flags specified here may either override the default flags or be added to them depending on the value of/crashreporter/overrideDefaultDumpFlags. This setting is ignored on Linux. For more information on the flags and their values, look upMiniDumpNormalon MSDN or see a brief summary above at Loading a Crash Dump to Investigate."/crashreporter/overrideDefaultDumpFlags": Indicates whether the crash dump flags specified in/crashreporter/dumpFlagsshould replace the default crash dump flags (whentrue) or simply be added to the default flags (whenfalse). This defaults tofalse. This setting is ignored on Linux."/crashreporter/compressDumpFiles": Indicates whether the crash report files should be compressed as zip files before uploading to the server. The compressed crash dump files are typically ~10% the size of the original, so upload time should be greatly reduced. This feature must be supported on the server side as well to be useful for upload. However, if this setting is enabled the crash reports will still be compressed locally on disk and will occupy less space should the initial upload fail. This defaults totrueas of Carbonite 208.0. Before Carbonite 208.0, this defaults tofalse."/crashreporter/retryCount": Determines the maximum number of times to try to upload any given crash report to the server. The number of times the upload has been retried for any given crash report is stored in its metadata. When the report files are first created, the retry count will be set to the 0. Each time the upload fails, the retry count will be incremented by one. When the count reaches this limit (or goes over it if it changes from the default), the dump file and its metadata will be deleted whether the upload succeeds or not. This defaults to 10."/crashreporter/crashReportBaseUrl": The base URL to use to print a message after a successful crash report upload. This message will include a URL that is pieced together using this base URL followed by the ID of the crash report that was just sent. Note that this generated URL is just speculative however and may not be valid for some small amount of time after the crash report has been sent. This setting is optional and defaults to an empty string. This setting should only be used in situations where it will not result in the URL for an internal resource being baked into a setting in builds that will go out to public users. This setting can be overridden by the environment variableOMNI_CRASHREPORTER_CRASHREPORTBASEURL."/crashreporter/includeEnvironmentAsMetadata": Determines whether the environment block should be included as crash report metadata. This environment block can be very large and potentially contain private information. When included, the environment block will be scrubbed of detectable user names. This defaults tofalse."/crashreporter/includePythonTraceback": Attempts to gather a Python traceback using the py-spy tool, if available and packaged with the crash reporter. The output from this tool will be a separate file that is uploaded along with the crash dump, configured by"/crashreporter/pythonTracebackFile". This defaults totrue."/crashreporter/pythonTracebackBinary": The binary to execute in order to capture a Python traceback. This allows the py-spy binary to exist under a different name if so desired. Defaults topy-spy.exeon Windows andpy-spyon non-Windows. May include a relative (to application working directory) or absolute path. If no directory is provided, first the same directory as the crash reporter is checked, followed by application working directory."/crashreporter/pythonTracebackArgs": Arguments that are passed to/crashreporter/pythonTracebackBinary. By default this isdump --full-filenames --nonblocking --pid $pidwhere$pidis a simple token that refers to the process ID of the crashing process. NOTE: py-spy will not work properly without at least these arguments, and overriding this key will replace these arguments, so these arguments should likely be included in your override."/crashreporter/pythonTracebackDir": The directory where the Python traceback is stored. May be an absolute path, or relative to the working directory of the process at the time the crash reporter is loaded. May be changed dynamically. This has an empty default, which means to use the same directory asdumpDir."/crashreporter/pythonTracebackName": The name of the Python traceback file. Any path separators are ignored. The default value is$crashid.py.txtwhere$crashidis a simple token that refers to the Crash ID of the crashing process–that is, the UUID generated by Breakpad at crash time. This file is created at crash time in the directory provided bypythonTracebackDirifincludePythonTracebackistrue. If the file cannot be created at crash time, no Python traceback file will be included. The simple token$pidis also available, which is the process ID of the crashing process."/crashreporter/pythonTracebackTimeoutMs": (default: 60000 [1 minute]) The time to wait (in milliseconds) for the Python-traceback process to run. If this time is exceeded, the process is terminated and no Python traceback will be available."/crashreporter/gatherUserStory": (default:true) When a crash occurs, carb.crashreporter-breakpad has the ability to run a process that gathers information from the user, such as steps to reproduce the problem or what the user specifically did. This value can be set tofalseto prevent gathering this information."/crashreporter/userStoryBinary": (default:crashreport.gui) The binary to execute to gather the crash user story."/crashreporter/userStoryArgs": (default:--/app/crashId=$crashid --/app/allowUpload=$allowupload) Arguments passed to the binary when it is executed."/crashreporter/userStoryTimeoutMs": (default: 600,000 [10 minutes]) The time to wait (in milliseconds) for the crash user story process to run. If this time is exceeded, the process is terminated and no crash user story will be available."/crashreporter/lowConfidenceOffsetBytes": (default: 10,240 [bytes]) A stack frame that has an offset of at least this many bytes will be flagged as[low-confidence]in the stack trace, as it is unlikely that the function named is not the actual function in source code. A stack frame will ignore this value if a source file name is successfully found in symbol information.
Internally Created Crash Metadata#
The crash reporter plugin itself will create several crash metadata values on its own. Many of these metadata key names are considered ‘reserved’ as they are necessary for the functionality of the crash reporter and for categorizing crash reports once received. There are also some other crash metadata values that are created internally by either the crash reporter or kit-kernel that should not be replaced or modified by other plugins, extensions, or configuration options. Both groups are described below:
Reserved Metadata Keys#
These key names are reserved by the crash reporter plugin. If an app attempts to set a metadata key under
the /crashreporter/data/ settings branch using one of these names, it will be ignored. Any Carbonite
based app will get these metadata values.
ProductName: Collected by the crash reporter plugin on startup. This value comes from either the/crashreporter/productor/app/namesetting (in that order of priority).Version: Collected by the crash reporter plugin on startup. This value comes from either the/crashreporter/versionor/app/versionsetting (in that order of priority).comment: Currently unused and unassigned, but still left as a reserved metadata key name.StartupTime: The time index at the point the crash reporter plugin was initialized. This will be expressed as the number of seconds since mignight GMT on January 1, 1970.DumpId: Collected at crash time by the crash reporter plugin. This is a UUID that is generated to ensure the generated crash report is unique. This ID is used to uniquely identify the crash report on any crash tracking system.CarbSdkVersion: Currently unused and unassigned, but still left as a reserved metadata key name. This named value is currently expressed through thecarboniteSdkVersionmetadata value.RetryCount: The number of retries that should be attempted to upload any crash report that is generated. This defaults to 0 and will be incremented with each failed attempt to upload the report. The default limit for this value is 10 attempts but can be modified with the/crashreporter/retryCountsetting.UploadSuccessful: Set to ‘1’ for a given crash report when it has been successfully uploaded. This value defaults to ‘0’. This value will always be ‘0’ locally and on any crash report management system except in the case where the/crashreporter/preserveDumpsetting is enabled.PythonTracebackStatus: Set to a status message indicating whether gathering the Python stack trace was successful or why it failed or was skipped.CrashTime: An RFC3339 GMT timestamp expressing when a given crash occurred.UserStory: The message entered into the ‘user story’ dialog by the user before uploading a crash report. This defaults to an empty string and will only be filled in if the/crashreporter/gatherUserStorysetting is enabled and the user enters text.UserStoryStatus: Set to a status message indicating whether gathering the user story was successful or why it failed or was cancelled.LastUploadStatus: Set to the HTTP status code of the last crash report upload attempt for a given report. This is only checked on attempting to upload a previously failed upload attempt.
Additional Metadata Collected at Crash Time#
These metadata values are collected by the crash reporter plugin when a crash occurs. These are collected in a safe manner by the crash reporter so that they don’t potentially lead to other problems. Any Carbonite based app will get these metadata values.
UptimeSeconds: The total number of seconds that the process ran for. This value is written when the crash report is first generated.telemetrySessionId: The telemetry session ID for the process. This is used to link the crash report to all telemetry events for the session.memoryStats: System memory usage information at crash time. This includes available and total system RAM, swap file, and virtual memory (VM) amounts for the process.workingDirectory: The current working directory for the process at the time of the crash. This value will be scrubbed to not include any user names if found.hangDetected: Set to ‘1’ if a hang is detected and that leads to an intentional crash.crashingThread: Set to the ID of the thread that was presumably detected as hung by the Kit hang detector. Currently this will always be the process’ main thread.crashingIntentionallyDueTo: Set to a reason message for why an intentional crash occurred. This is only present if the crash was intentional and not the result of a program malfunction or bug.
Metadata Collected on Crash Reporter Startup#
These metadata values are collected by the crash reporter during its startup process. Any values that include user names or user IDs will be scrubbed before setting the values. Any Carbonite based app will get these metadata values.
commandLine: The full command line that was used to launch the process. This will be scrubbed for user names before being added.environment: Lists all environment variables present at process launch time. This metadata value is disabled by default but can be enabled with the/crashreporter/includeEnvironmentAsMetadatasetting. All environment variables will be scrubbed for user names before being added as metadata.runningInContainer: Boolean indicating if the process is running in a container.
Metadata Collected on Kit-Kernel Startup#
These metadata values are collected by Kit-kernel during its startup. Some of these values will only be collected for internal runs of Kit based apps. Any Kit based app will get these metadata values.
environmentName: The runtime environment the app is currently running in. This will either be the name of any detected CI/CD system (ie: TeamCity, GitLab, etc), or ‘default’ if none is detected. This will also be modified later by theomni.kit.telemetryextension to be set to either ‘Individual’, ‘Enterprise’, or ‘Cloud’ if it was previously set to ‘default’.appState: Set to either ‘startup’, ‘started’, or ‘shutdown’ depending on which stage of the kit-kernel life cycle the process is currently in.carboniteSdkVersion: The version of the Carbonite SDK that is in use.carboniteFrameworkVersion: The version of the Carbonite framework that is in use.appName: The name of the app that is currently running.appVersion: The version of the app that is currently running.portableMode: Set to ‘1’ if the--portableand--portable-rootcommand line options are used or a portable root is implicitly setup in a local developer build. Set to ‘0’ otherwise.email: Set to the user’s email address as reported in theirprivacy.tomlfile. Note that this value will not be present inprivacy.tomlfor public users.userId: Set to the user’s ID as reported in theirprivacy.tomlfile. Note that this metadata value will not be set for public users.
Metadata Added From Assertion Failures#
These metadata values are only added when a CARB_ASSERT, CARB_CHECK, CARB_RELEASE_ASSERT, or CARB_FATAL_UNLESS
test fails. These provide information on why the process aborted due to a failed assertion that was not
caught and continued by a debugger. Any Carbonite based app will get these metadata values.
assertionCausedCrash: Set to ‘true’ if the crash was caused by a failed assertion. This value is not present otherwise.assertionCount: Set to the number of assertions that had failed for the process. For most situations this will just be set to ‘1’. However, it is possible to continue from a failed assertion under a debugger at least so this could be larger than 1 if a developer continued from multiple assertions before finally crashing.lastAssertionCondition: The text of the assertion condition that failed. This will not include any values of any variables mentioned in the condition however.lastAssertionFile: The name and path of the source file the assertion failed in.lastAssertionFunc: The name of the function the assertion failed in.lastAssertionLine: The source code line number of the failed assertion.
Metadata Added When Extensions Load#
These metadata values are added by the extension loading plugin in Kit-kernel. These will be present only in certain situations in Kit based apps. Any Kit based app will get these metadata values.
extraExts: Set to the list of extensions that the user has explcitly installed or toggled on or off during the session. This is done through the extension manager window in Kit apps. Extension names will be removed from this list any time an extension is explicitly unloaded by the user at runtime.autoloadExts: Set to the list of extensions that the user has explicitly marked for ‘auto-load’ in the Kit extension manager window. This value will only be written out once on startup.