Architecture#
Architectural Principles#
A few important architectural principles guide the design of the software and have been captured here. It’s important you know these principles since they will help you understand our design decisions and guide you when faced with design trade-offs.
Customer first#
The customer comes first, we come second
Always think about the customer experience, i.e. the developer, who will be utilizing this framework to build applications and/or plugins. The customer comes first, we come second. For example, we seek to minimize the work that developers have to do to transform their existing SDKs into Carbonite plugins.
We also understand that our customers’ time is precious, this is why we optimize the build process so they can rapidly build-inspect-learn. Another manifestation of this principle is that we work directly with customers to design the right solution for their needs. Our design is therefore iterative, we don’t believe that we can anticipate all of our customers’ needs - we must find them and work with them.
Finally, we see ourselves in the role of janitors for the Carbonite Framework. Even though we work hard to make this Framework shine, the truly magical technology will be made by the people that use Carbonite to build plugins and applications. Our role is to facilitate and get out of the way of innovation.
Simplicity#
Achieve more with less
We strive for solutions that are elegant in their simplicity. These solutions are harder to design but they result in a system that is easier for our customers to understand and control. As an added bonus for us, these systems are also easier to maintain. Think about the cognitive load you put on customers with your design; even if the C++ standard allows you to do something doesn’t necessarily mean it’s a good idea.
Don’t add code unless it’s needed. Unused code is like untested code. It’s a liability. Even if you think something could be useful in the future please defer adding it until it’s actually needed. This also means that if you make code redundant you must remove it. We can always recover it later using source control, if needed.
Zero impact to your environment#
Don’t make a mess and expect others to deal with it
We should minimize our dependency on local machine configuration, the goal is zero. This principle guides us to configure our code and build processes such that our repository builds directly from source control, without any manual configuration. There is an added bonus here: all of our configuration is accurately captured in the repository and therefore versioned and branched with the associated source code.
This principle also guides us to prevent leaks of our configuration into the environment; example of this is our requirement that the runtime is statically linked into the modules and that the choice of compiler is abstracted via the Carbonite ABI. If we didn’t do this our users would have to install the corresponding runtime to run Carbonite-based applications and developers would have to use the same compiler that was used to build the modules of Carbonite. Both of these would be examples of us spilling our internal choices into the environment.
It is admittedly extra work to contain your work this way but the benefit is reaped by all the users and developers and that makes it worth it. This is also in line with our architecture principle of customers coming first and us coming second.
Don’t reinvent the wheel#
Use well-tested internal and external code when possible
There are some things that Carbonite is good at, and other things best left to people and projects that have hardened, well-tested implementations that we can make use of, both inside and outside of NVIDIA. Licensing from heavily-tested and hardened projects will allow us to more quickly develop solutions to our customers’ needs. In some cases, we recognize that there is a need to adapt certain code to Carbonite’s style and methodology (such as with Boost constructs). Boost is not desired due to increase in complexity and compile times.
We should also make liberal use of the available constructs in the C++ STL, including containers. However, there are some places where the standard set of containers falls short, or where performance testing shows a bottleneck that can only be solved by an algorithmic shuffling. There is a significant cost to writing a new container, both in time to develop and thoroughly test, but also in maintenance and understanding by future developers. For containers specifically, a set of criteria exists that must pass muster with the Carbonite team before a container should be written:
What is the immediate business need?
What shortcomings of the existing container set creates the need for a new container?
Does the new container cause a 10%+ increase in performance over the required operation?
Can the new container achieve 100% code coverage in tests?
Truly modular#
Make ravioli - not spaghetti
In a lot of software documentation you will find references to “modular architecture” but in reality few of them have true modularity. Many systems that advertise modularity only have virtual modularity, i.e. the source code has been grouped into clusters of related functionality but these clusters must all be built together using the same build system/compiler and there isn’t a versioned ABI between the clusters. This type of modularity is understandable because true modularity comes at a cost. For instance, as part of the ABI you cannot leak memory management outside of your plugin. E.g. if you use the STL internally you cannot leak this decision out of your plugin because in doing so you force others to use the same STL and runtime. We recommend that the runtime be statically linked so that others don’t have to deal with your dependencies - they could be using a different version (see “Zero impact to your environment” principle). Another cost of the ABI is that the interfaces need to be maintained separately and versioned. When changes are made that affect the interface the version number needs to be adjusted accordingly (see later sections for details).
In our case this is cost that we can justify because our goal is to make a framework that helps (rather than hinders) us in sharing different technologies developed and maintained by different groups within NVIDIA. The versioned Application Binary Interface (ABI) is our binding contract. It enables the sharing of pre-built and pre-verified Carbonite plugins between teams, in stark contrast to the fork-and-really-hard-to-merge strategy that we’ve had to employ with the monolithic source code repos of the past. Consumers of Carbonite plugins will not have to rig up build environments that match what the producing teams used. This also frees the producing teams to use whatever technology they want to build their plugins. For example, if they want to use the latest bleeding edge version of CUDA they can do so - but not burden anybody else with that choice or burden them with having to build your binaries from your CUDA source files.
Quality assurance is our responsibility#
When we break things, we should be the first to know
Quality assurance of the Carbonite framework and foundational plugins is our responsibility. We write unit tests and system tests and run them in automated fashion. We implement test doubles for plugins and functionality that is too costly or should not be run as part of testing. We respond to test failures and bad tests are either improved or eliminated. The plugin architecture helps significantly here because the interface and the function of a plugin that implements it can be validated using black box testing.
Rapid value delivery#
Always be delivering
The modular architecture allows subsystems to be developed and iterated on in isolation. This makes the time from “code change to testable build” short. Built-in support that allows plugins to be reloaded at runtime shortens the change to test time, since changes can be tested interactively without relaunching and re-configuring for the test.
Data-driven#
Allow the data to drive, rather than our assumptions
Measure before you decide to optimize your code, don’t assume you know where the bottleneck is. This principle requires us to provide great support for tools that enable measurement, like profiling. But this principle is farther reaching than just profiling and optimization. Our architecture should be highly configurable via data. We should avoid locking in behavior and assumptions into the code when we know that users will require flexibility. This will also facilitate A/B testing which is highly beneficial, not only for comparing a new solution to and old one, but also provides a fallback strategy if we identify catastrophic problems with the new approach. In this type of scenario it’s often called a “feature flag”, i.e. there is a way via data to enable a feature in the code. Embrace this method of working, integrate new features or new versions as alternate code paths while they are being proven out. Additionally, when designing systems we should design them from the data and up; think about the most efficient layout for the data and how we can fit an efficient but still user friendly interface on top of that.
Architectural Overview#
Carbonite is a lightweight framework for building applications.
It is the opposite of a monolithic software system since capabilities and features are encapsulated in plugins with versioned interfaces.
This allows the assembly of an application from binary plugins, developers choose what to use. They can leave behind the plugins they don’t need, improve the implementations of those that don’t meet their needs, and build the plugins that are missing for their use case.
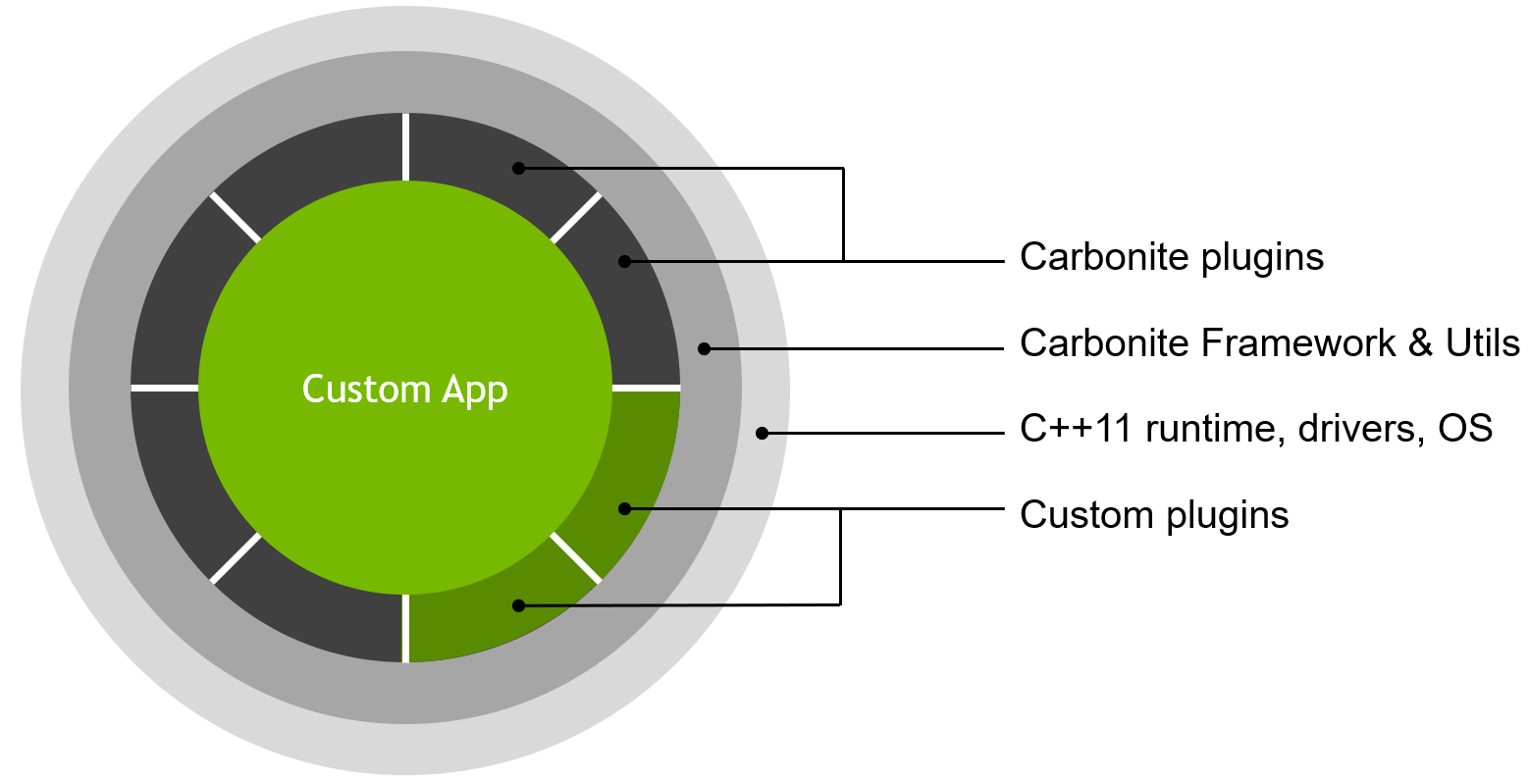
A Carbonite application is composed of
application code,
custom plugins, and
Carbonite plugins.
These are all written on top of the
Carbonite Framework & Utils,
C++11 runtime, operating system, and drivers.
Architecture diagram#
Namespaces#
Anyone looking through public Carbonite header will notice that there are two top-level namespaces used - carb and omni. These two namespaces should typically be seen as both being the project level organizational namespaces for Carbonite, but have historical significance. Originally the Carbonite library started out with everything being part of the carb namespace. This provided top-level organization and symbol scoping early on during development. Later in development of the SDK, the Omniverse Native Interfaces (ONI) system was added. with this came the introduction of the omni namespace. Generally, new development is encouraged to utilize ONI and exist in the omni namespace. For backwards compatibility and to limit downstream maintenance effects, existing items in the carb namespace are retained and used.
Plugins, Framework, and Utils#
It is important to emphasize that how developers split an application into application code vs plugin code is up to them. We encourage developers to use existing plugins if they meet their needs. Carbonite is however designed in such a way that most pieces can be omitted. Of the three building blocks:
Framework
Utils
Plugins
Only the Framework is mandatory and it is quite small. It provides essential services, like FileSystem, extendable LogSystem, and plugin management. All other services in Carbonite are provided by plugins and utility code. It should be emphasized here that Carbonite doesn’t attempt to cover all services that you may need. Instead we expand the catalog as we build useful plugins with customers or harvest plugins built entirely by customers. The plugins the Carbonite team maintains are developed in the Carbonite repo. Plugins developed and maintained by other teams are often called custom plugins. Those are housed outside the Carbonite repo, typically in the application repo or a separate repo if the plugin is being shared across multiple applications.
The general rule we’ve followed in designing Carbonite is the following:
If a system is optional or we expect multiple implementations of it we make it a plugin.
Of course we only do this for systems. For smaller utility code we use the header-only Carbonite Utils library. In there you will find unicode conversion functions and path manipulation utilities, to name a few.
Plugins must follow strict rules in how they are built so that they can be shared as binary artifacts:
Carbonite is 64-bit only. This means you can gleefully ignore making 32-bit versions of your plugins. Carbonite supports Linux-x86_64, Linux-aarch64 (Tegra) and Windows-x86_64. A plugin needs to include an implementation for these platforms (Windows and Linux) to be considered for adoption by the Carbonite team.
A semantically versioned C-style ABI must be exposed by the plugin and used by clients.
It should be noted here that these are the rules that all Carbonite plugins must live by, so that they can be shared as binary artifacts. In custom plugins you have more flexibility and can decide to sacrifice these benefits but those plugins cannot be accepted into the Carbonite repo. Doing so would violate our Architectural principles of Truly modular and Zero impact to your environment.
If your plugin is foundational and follows the rules above it can be submitted in source code form to the Carbonite
repo, along with premake build scripts. The plugin interface
would be stored under include/carb/<plugin-interface-name> and contained in namespace
carb::<plugin-interface-name>. All other files, including implementation would be stored under
source/plugins/<plugin-interface-name>. If there are multiple implementations of the interface the different
implementations are separated by postfixing -<implementation-name> to the plugin. For example:
source/plugins/carb.graphics-vulkan and source/plugins/carb.graphics-direct3d.
If you are writing a custom plugin you would do this similarly
but choose a different top level namespace from carb and therefore another folder under include to store the
interface.
Thread safety#
Our approach to thread safety is as follows in Carbonite:
If nothing else is specified in the documentation of a system then locking is left to the application.
Where this is not feasible we create an API that is lock friendly (begin/end/commit) and document where locking must be performed (commit)
Last resort is to lock internally. This is only done where it’s not feasible to push this control up the stack (e.g. logger writing a message to a file or console).
The Framework itself is thread-safe in that multiple threads can acquire and release interfaces simultaneously. In an effort to allow maximum forward progress, the Framework lock is not held while a plugin is initialized.
ABI and versioning#
As already mentioned Carbonite employs a versioned C-style ABI (Application Binary Interface) to facilitate easy sharing of plugins. This is a stronger contract than an API (Application Programming Interface) because an API doesn’t guarantee binary compatibility. A module with a versioned API will commonly require consumers to rebuild their source code against the new version of the API. Put differently, just replacing the built binary with a new version will in most cases be disastrous.
By comparing and contrasting these scenarios the terms source compatible and binary compatible emerge. For this discussion we will use the term external source code for all code that is outside the module. This code can be in other modules or application side. A change to a module is only source compatible when
changes to external source code are not required
a rebuild of external source code is required
An example of this is when adding data members to a transparent data type by expanding the data type. This type of change will not require any code changes externally but a rebuild is required of all the external code because the size of the data structure has changed. A change is both source and binary compatible when
changes to external source code are not required
a rebuild of external source code is not required
It’s important to note that most engines and middleware are designed so that new versions can only be source compatible, which forces sharing to happen on the source code level rather than binary artifact level. As we covered earlier, Carbonite needs to be truly modular which means that many changes to plugins can be done in a binary compatible manner.
In the example above, adding data members to a transparent data type, can be achieved in a binary compatible manner by extending the data type via indirection. The pattern is as follows, a transparent data type contains an extension member at the end. This member is only used when the data type needs to be extended. For example:
// This is version 1.0
struct ImageDesc
{
int width;
int height;
void* ext; // This is to future proof the struct. Type is void because it's not used in v1.0.
};
// Usage:
ImageDesc i = {1024, 1024}; // compiler initializes 'ext' to nullptr, in both debug and release builds.
Later we realize that we want to support an optional name for these images as well, so we expand:
struct ImageDescExt;
// This is version 1.1
struct ImageDesc
{
int width;
int height;
ImageDescExt* ext; // The pointer has now become typed, sending a clear signal that it can be used.
};
struct ImageDescExt
{
const char* name;
void* ext; // This is to future proof the ImageDesc struct. Type is void because it's not used in v1.1
};
// Usage:
ImageDescExt e = {"my_awesome_image"};
ImageDesc t = {1024, 1024, &e};
As you can see the size of each struct doesn’t changes, we just chain new data via the ‘ext’ member, and the compiler automatically sets the ‘ext’ member to nullptr when you initialize the struct using an initializer list. This gives us binary compatibility when extending an established plugin with optional features. When these new features are not optional we of course bump the major version number and in that case the client must make code changes to accommodate the interface changes that have been made. In the case above this would lead to changing the data layout of the struct, like this:
// This is version 2.0 - previous versions and extensions have been wiped
struct ImageDesc
{
const char* name;
int width;
int height;
void* ext; // This is to allow extensions in minor version upgrades. Type is void because it's not used in v2.0
};
// Usage:
ImageDesc t = {"my_awesome_image", 1024, 1024};
Notice how we purposefully re-order the data members in the v2.0 of the struct. This is to cause compilation errors
where the struct is being initialized - because those call sites need to be revisited when upgrading to this new major
version of the plugin interface. If we are paranoid about this case we could also rename it for version 2.x, to
ImageDesc2. That is bound to generate compiler errors everywhere external code interacts with it.
In Carbonite we use structs for grouping together input parameters because that way we can extend the list of parameters while still maintaining binary compatibility. The plugin interface functions are also exposed via structs but these are never created by clients, they are acquired from the plugin and released by calling the plugin. This means that newer versions of the plugin can introduce optional functions that an older client won’t know about but this will cause no harm because the struct is always created by the plugin and thus always of the correct size. These structs can even contain state data that is opaque to the client. It is therefore perhaps appropriate to call them semi-transparent structs in terms of client visibility.
A plugin will expose a main interface structs. To avoid complicated versioning we use one version number to capture the version of a plugin interface and store this in the main interface struct. If the plugin exposes other interface structs (sometimes referred to as sub-interfaces) those must be fetched via the main interface struct. This guarantees that version checks are performed because the main interface must be acquired first. Let’s illustrate this with an example, using the Input plugin:
namespace carb
{
namespace input
{
// this is a sub-interface - we keep it outside the main interface for cleanliness because most
// users will never use this interface, it is used by other plugins that handle input devices.
struct InputProvider;
struct Input
{
CARB_PLUGIN_INTERFACE("carb::input::Input", 1, 0)
/**
* Get keyboard logical device name.
*
* @param keyboard Logical keyboard.
* @return Specified keyboard logical device name string.
*/
const char*(CARB_ABI* getKeyboardName)(Keyboard* keyboard);
/*
* Lots of code here with different Input interface functions, pages of really well documented and well
* designed functions. Honestly. Check it out at source/plugins/carb/input/Input.h.
*/
/**
* Returns input provider's part of the input interface.
*
* @return Input provider interface.
*/
InputProvider*(CARB_ABI* getInputProvider)();
};
}
}
If we need to make a change to the InputProvider interface struct we bump the version number for the Input plugin
interface. In the example above the version is major 1 and minor 0, so 1.0. Before we discuss the rules of how those
numbers change let’s summarize what we just discussed:
A plugin interface is the collection of all the headers that a plugin exposes. Any change to this interface requires that you modify the plugin version. The main interface struct is always acquired via the
Framework::acquireInterfacefunction that will perform version checks for you. Sub-interfaces must only be accessible via this main interface (usinggetfunctions or a factory pattern).
Now we turn our attention to the rules of how we set and adjust the version numbers.
A plugin interface has a major and minor version number:
Major version is increased every time a non-backwards compatible change is made. Please realize that this means any aspect of the interface, including sub-interfaces, essentially any header that is externally accessible in the root folder for the plugin.
Minor version is increased every time a backwards compatible change is made to the interface of the plugin. This can involve adding a new optional function to the API. Clients of the interface can therefore use plugins that implement this new interface even if they were compiled against a lower minor version (since the additions are optional and these types of changes are binary compatible).
A plugin implementation has a major version, minor version, and build identifier:
Major version matches the interface that this implementation supports
Minor version matches the interface that this implementation supports, and all lower minor versions of that same major version.
Build identifier is a string that uniquely identifies the build, usually composed of repo name, branch name, and build number. It may also include git hash for easy identification of latest commit included. This string is set to “dev” on development builds.
Please endeavor to not bump major version unless absolutely needed. Interface changes cause pain for users of the plugin and plugins that constantly bump their major version will not be popular. Quite to the contrary, users will avoid them. Instead, spend the time and energy to make your changes backwards compatible if at all possible. Then save up for a larger refactoring that can be done at an opportune time where multiple changes are made at once to the interface. If you find it difficult to make backwards compatible changes please consult with the Carbonite team, they have experience that can hopefully help.
It should be clear from reading this that creating an ABI and managing changes so they cause the least disruption to clients requires dedication and resourcefulness. You should therefore only expose necessary functionality in a plugin interface. Optional and nice-to have things are better provided in source code form via the header-only utils library.
Avoiding Dependency Issues#
Even changing minor versions can have a knock-on effect for dependency management. Consider this tale of woe:
In October 2023, the
carb::logging::ILoggingversion was increased to 1.1 to add several functions. Though these functions were only going to be used in certain (specific) circumstances, any addition necessitates a version increase.At some later point this version of Carbonite (v156.0) was adopted by downstream customers. Omniverse Extensions were built against this version of Carbonite and implicitly picked up the
ILogging1.1 version requirement.For whatever reason, two distinct Omniverse Kit applications both adopted version 105.2, but were based on different branches of code that used different Carbonite versions: one with the
ILogging1.1 change and one without.Extensions that were built against the “newer” 105.2 (with
ILogging1.1) were no longer compatible with the “older” 105.2 since they implicitly requiredILogging1.1 without needing any additional functionality from it.
After discussing this point in Carbonite Office Hours, OVCC-1472 was created to document this phenomenon and attempt to find a solution. Essentially the solution is this: version changes must be opted into. This means that when it becomes necessary to bump an interface’s version, we maintain the previous version as the “default” version. If an extension/module/application requires use of the new functionality that application must declare this by requesting the newer version of the interface.
This new method is recommended for all new interfaces, and should be switched to when a change to an existing interface is required (maintaining the previous version as the default version).
In order to do this, interfaces must be declared slightly differently. First, macros should be declared that define the latest version and the default version (which may be different). This cannot be generated by normal means (i.e. macros) and therefore must follow this boilerplate code:
//! Latest version for carb::logging::ILogging
#define carb_logging_ILogging_latest CARB_HEXVERSION(1, 1)
#ifndef carb_logging_ILogging
//! The default current version for carb::logging::ILogging
# define carb_logging_ILogging CARB_HEXVERSION(1, 0)
#endif
The recommended naming paradigm is to take the fully-qualified interface struct name with :: changed to _ to make
the name valid. The latest version has a _latest suffix and is always defined. The current version does not have a
suffix and is only defined if not already defined. This allows project settings to override the define by specifying on
the compiler command line (example: -Dcarb_logging_ILogging=carb_logging_ILogging_latest or
-Dcarb_logging_ILogging=CARB_HEXVERSION(1,1)).
NOTE: The module that implements the interface must have <current version>=<latest version> in its project
settings or passed on the compiler command line.
Next, the interface must be declared with CARB_PLUGIN_INTERFACE_EX instead of CARB_PLUGIN_INTERFACE:
CARB_PLUGIN_INTERFACE_EX("carb::logging::ILogging", carb_logging_ILogging_latest, carb_logging_ILogging)
And finally, use the CARB_VERSION_ATLEAST macro with #if to conditionally include versioned code:
#if CARB_VERSION_ATLEAST(carb_logging_ILogging, 1, 1)
/**
* Retrieves the extended StandardLogger2 interface from an old \ref StandardLogger instance.
* @param logger The logger to retrieve the instance from. If `nullptr` then `nullptr` will be returned.
* @returns The \ref StandardLogger2 interface for \p logger, or `nullptr`.
*/
StandardLogger2*(CARB_ABI* getStandardLogger2)(StandardLogger* logger);
// ...
#endif
Deprecation and Retirement#
Given the goal above to minimize changes to major versions and allow backwards compatibility through minor version changes, a technique is employed to deprecate and retire functions.
Step 1: Deprecation#
Along with a minor version increment, a function may be decorated with CARB_DEPRECATED, which signals intent
that the function will be eventually removed and further use of this function is discouraged. This breaks source compatibility
in that a warning will be generated when using the function (if such warnings are enabled), but does not affect
binary compatibility. The function must remain in the plugin, and must remain at the same location within the plugin’s
interface.
Step 2: Retirement#
At least a calendar month later, and with another minor version increment, a function may be retired by appending
_RETIRED_V(x)_(y) to the function name, where (x) is the major version and (y) is the minor version after
increment. The function should still remain in the plugin, and must remain at the same location within the plugin’s
interface. The modification of the function name will absolutely break source compatibility but will still not affect
binary compatibility.
Step 3: Optional removal#
At least a calendar month later, and with another minor version increment, a function may be removed by changing its
location within the interface struct to be nullptr or replacing the function with a stub function that performs a
CARB_FATAL_UNLESS(false, ...) with an error message. It is important that the location within the interface struct
does not change in order to maintain binary compatibility. NOTE: This change breaks binary compatibility for the removed
function but maintains overall binary compatibility. This is only recommended when it is highly unlikely that any
dependencies exist for older versions of the interface.
Step 4: Removal and cleanup#
When the next major version bump happens, all references to the function may be removed, and the nullptr or stub
function may be removed from the interface struct. A common and recommended method for decorating code with reminders to
remove elements is to place static_assert statements for the major version equal to the current value. When the major
version is incremented, the various static_assert statements will trigger errors that serve as reminders to perform
clean up.
Folder Structure#
Module |
Source location |
Namespace |
Binary name |
|---|---|---|---|
Carbonite Framework |
|
|
carb.dll, libcarb.so |
Carbonite Extras |
|
|
header only |
Carbonite Plugins |
|
|
|
Carbonite Libraries |
|
|
|
Carbonite Python Bindings |
|
|
|
Carbonite Public Headers |
|
|
header only |
Carbonite Internal Shared Headers |
|
|
header only |
Carbonite C++ Unit Tests |
|
user defined |
user defined |
Carbonite Python Unit Tests |
|
none |
none |
Carbonite Runtime Tools |
|
user defined |
|
Carbonite Example Apps |
|
user defined |
|
Carbonite Dependencies |
|
none |
none |
Carbonite Documentation |
|
none |
none |
Carbonite Build Tools |
|
none |
none |
Custom App |
user defined |
user defined |
<user-defined>.exe |
Custom Plugins |
user defined |
anything but |
<user-defined>.plugin.{dll|so} |
File and folder naming conventions we use:
In general, the header files under the
include/andsource/include/folders should go into folders matching the C++ namespace that is used inside the header itself. For example, theIStructuredLog.hheader uses theomni::structuredlognamespace internally so this header should go in the folderinclude/omni/structuredlog/.Source files for a plugin or library’s implementation should go in a folder under
/source/plugins/or/source/libs/respectively. The folder should be named after the plugin or library project’s name. In general this should take the form{carb|omni}.<pluginName>[-<backendDependency>]where<pluginName>is the Carbonite specific name for the plugin (ie: “crashrepoter”, “structuredlog”, “events”), and<backendDependency>is the name of the external or OSS SDK that has been used to implement the plugin if any. For example, thecarb.crashreporter-breakpadplugin uses Google’s Breakpad project to handle much of the plugin’s functionality. If no third party library is used to implement the plugin, this portion of the name can be omitted.All folder paths should be lower case.
All C++ source or header filenames should be PascalCase.
All Python filenames should be lower case snake_case.
All header files that declare interfaces (public or private headers) must start with
I.