Testing Extensions with Python
This guide covers the practical part of testing extensions with Python. Both for extensions developed in the kit repo and outside.
For information on testing extensions with C++ / doctest, look here, although there is some overlap, because it can be preferable to test C++ code from python bindings.
The Kit Sdk includes the omni.kit.test extension and a set of build scripts (in premake5-public.lua file) to run extension tests.
It supports two types of testing:
python tests (
unittestwithasync/awaitsupport)c++ tests (
doctest)
It is generally preferred to test C++ code from python using bindings where feasible. In this way, the bindings are also tested, and that promotes writing bindings to your C++ code. Most of this guide focuses on python tests, but there is a C++ section at the very end.
Adding Extension Test: Build Scripts
If your extension’s premake5.lua file defines the extension project in usual way:
local ext = get_current_extension_info()
project_ext (ext)
It should already have corresponding bat/sh files generated in the _build folder, e.g.: _build\windows-x86_64\release\tests-[extension_name].bat
Even if you haven’t written any actual tests, it is already useful. It is a startup/shutdown test, that verifies that all extension dependencies are correct, python imports are working, and that it can start and exit without any errors.
An empty extension test entry is already an important one. Wrong or missing dependencies are a source of many future issues. Extensions are often developed in the context of certain apps and have implicit expectations. When used in other apps they do not work. Or when the extension load order randomly changes and other extensions you implicitly depend on start to load after you.
How does it work?
You can look inside Kit’s premake5-public.lua file to find the details on how it happens, follow the function project_ext(ext, args).
If you look inside that shell script, it basically runs an empty Kit + omni.kit.test + passes your extension. That will run the test system process which in turn will run another, tested process, which is basically: empty Kit + omni.kit.test + --enable [your extension].
The test system process prints each command it uses to spawn a new process. You can copy that command and use exactly the same command for debugging purposes.
You may ask why we spawn a process, which spawns another process? And both have omni.kit.test? Many reasons:
Test system process monitors tested process:
It can kill it in case of timeout.
Reads return code. If != 0 indicates test failure.
Reads
stdout/stderrfor error messages.
Test system process reads
extension.tomlof the tested extension in advance. That allows us to specify test settings, cmd args, etc.It can run many extension tests in parallel.
It can download extensions from the registry before testing.
omni.kit.test has separate modules for both test system process (exttests.py) and tested process (unittests.py).
Writing First Test
Tested process runs with omni.kit.test which has the unittests module. It is a wrapper on top of python’s standard unittest framework.
It adds support for async/await usage in tests. Allowing test methods to be async and run for many updates/frames. For instance, a test can at any point call await omni.kit.app.get_app().next_update_async() and thus yield test code execution until next update.
All the methods in the python standard unittest can be used normally (like self.assertEqual etc).
If your extension for instance is defined:
[[python.module]]
name = "omni.foo"
Your tests must go into the omni.foo.tests module. The testing framework will try to import tests submodule for every python module, in order to discover them. This has a few benefits:
It only gets imported in the test run. Thus it can use test-only dependencies or run more expensive code. There is no need to depend on
omni.kit.testeverywhere.It gets imported after other python modules. This way public modules can be imported and used in tests as if the tests are written externally (but still inside of an extension). In this way, the public API can be tested.
An actual test code can look like this:
# NOTE:
# omni.kit.test - python's standard library unittest module with additional wrapping to add support for async/await tests
# For most things refer to the unittest docs: https://docs.python.org/3/library/unittest.html
import omni.kit.test
# Import extension python module we are testing with absolute import path, as if we are an external user (i.e. a different extension)
import example.python_ext
# Having a test class dervived from omni.kit.test.AsyncTestCase declared on the root of the module will make it auto-discoverable by omni.kit.test
class Test(omni.kit.test.AsyncTestCase):
# Before running each test
async def setUp(self):
pass
# After running each test
async def tearDown(self):
pass
# Actual test, notice it is an "async" function, so "await" can be used if needed
async def test_hello_public_function(self):
result = example.python_ext.some_public_function(4)
self.assertEqual(result, 256)
All the concepts here are from the standard unittest framework. Test methods start with test_. You need to inherit a base test class, which will be created, setUp() will be called before each test, tearDown() after. Everything can be async or “sync”.
Test Settings
Test Settings: Basics
The [[test]] section of extension.toml allows control of how to run a test process. We aim to make that configuration empty and for the defaults to be reasonable. We also strive to make tests run as close as possible to a real-usage run, making test environments the same as production.
However, you can specify which errors to ignore, what additional dependencies to bring, change the timeout, pass extra args etc. All the details are in Kit’s Extensions doc.
Below is an example, it shows how to:
add extra arguments
add test only dependencies (extensions)
change timeout
include and exclude error messages from failing tests
[[test]]
args = ["--/some/setting=1"]
dependencies = ["omni.kit.capture.viewport"]
timeout = 666
stdoutFailPatterns.include = ["*[error]*", "*[fatal]*"]
stdoutFailPatterns.exclude = [
"*Leaking graphics objects*", # Exclude graphics leaks until fixed
"*[carb.crashreporter-breakpad.plugin] [previous crash]*", # Ignore crashes from previous runs
]
Test Settings: Where to look for python tests?
By default test system process (exttests.py) reads all [[python.module]] entries from the tested extension and searches for tests in each of them. You can override it by explicitly setting where to look for tests:
[[test]]
pythonTests.include = ["omni.foo.*"]
pythonTests.exclude = ["omni.foo.bar.*"]
This is useful if you want to bring tests from other extensions. Especially, when testing apps.
Test Settings: Multiple test processes
Each [[test]] entry is a new process. Thus by default, each extension will run one test process to run all the python tests for that extension.
When adding multiple entries they must be named to distinguish them (in artifacts, logs, etc):
[[test]]
name = "basic"
pythonTests.include = [ "omni.foo.*basic*" ]
[[test]]
name = "other"
pythonTests.include = [ "omni.foo.*other*" ]
To select which process to run: pass -n [wildcard], where [wildcard] is a name. * are supported:
> _build\windows-x86_64\release\tests-example.python_ext.bat -n other
Test Settings: Disable test on certain platform
Any setting in extension.toml can be set per platform, using filters. Read more about them in “Extensions” doc. For example, to disable tests on Windows, the enabled setting can be overridden:
[[test]]
name = "some_test"
"filter:platform"."windows-x86_64".enabled = false
Running Your Test
To run your test just call the shell script described above: _build\windows-x86_64\release\tests-[extension_name].bat.
Run subset of tests
Pass -f [wildcard], where [wildcard] is a name of the test or part of the name. * are supported:
> _build\windows-x86_64\release\tests-example.python_ext.bat -f "public_function"
Run subset of tests using Tests Sampling
Pass --/exts/omni.kit.test/testExtSamplingFactor=N, where N is a number between 0.0 and 1.0, 0.0 meaning no tests will be run and 1.0 all tests will run and 0.5 means 50% of tests will run.
To have this behavior on local build you need an additional parameter: --/exts/omni.kit.test/testExtSamplingContext='local'
> _build\windows-x86_64\release\tests-example.python_ext.bat --/exts/omni.kit.test/testExtSamplingFactor=0.5 --/exts/omni.kit.test/testExtSamplingContext='local'
Run tests from a file
To run tests from a file use --/exts/omni.kit.test/runTestsFromFile='' with the name of the file to read.
Note: each time the tests run a playlist will be generated, useful to replay tests in a specific order or a subset of tests.
> _build\windows-x86_64\release\tests-example.python_ext.bat --/exts/omni.kit.test/runTestsFromFile='C:/dev/ov/kit/exttest_omni_foo_playlist_1.log'
Retry Strategy
There are 4 supported retry strategies:
no-retry-> run tests onceretry-on-failure-> run up to N times, stop at first success (N =testExtMaxTestRunCount)iterations-> run tests N times (N =testExtMaxTestRunCount)rerun-until-failure-> run up to N times, stop at first failure (N =testExtMaxTestRunCount)
For example to retry tests up to 3 times (if a flaky test occurs) use this command:
> _build\windows-x86_64\release\tests-example.python_ext.bat --/exts/omni.kit.test/testExtRetryStrategy='retry-on-failure' --/exts/omni.kit.test/testExtMaxTestRunCount=3
Developing Tests
Pass --dev or --/exts/omni.kit.test/testExtUIMode=1. That will start a window with a list of tests instead of immediately running them. Here you can select tests to run. Change code, extension hot reloads, run again. E.g.:
> _build\windows-x86_64\release\tests-example.python_ext.bat --dev
Note that this test run environment is a bit different. Extra extensions required to render a basic UI are enabled.
Tests Code Coverage (Python)
Pass --coverage. That will run your tests and produce a coverage report at the end (HTML format):
> _build\windows-x86_64\release\tests-example.python_ext.bat --coverage
The output will look like this:
Generating a Test Report...
> Coverage for example.python_ext:default is 49.8%
> Full report available here C:/dev/ov/kit/kit/_testoutput/test_report/index.html
The HTML file will have 3 tabs. The coverage tab will display the coverage per file. Click on a filename to see the actual code coverage for that file.
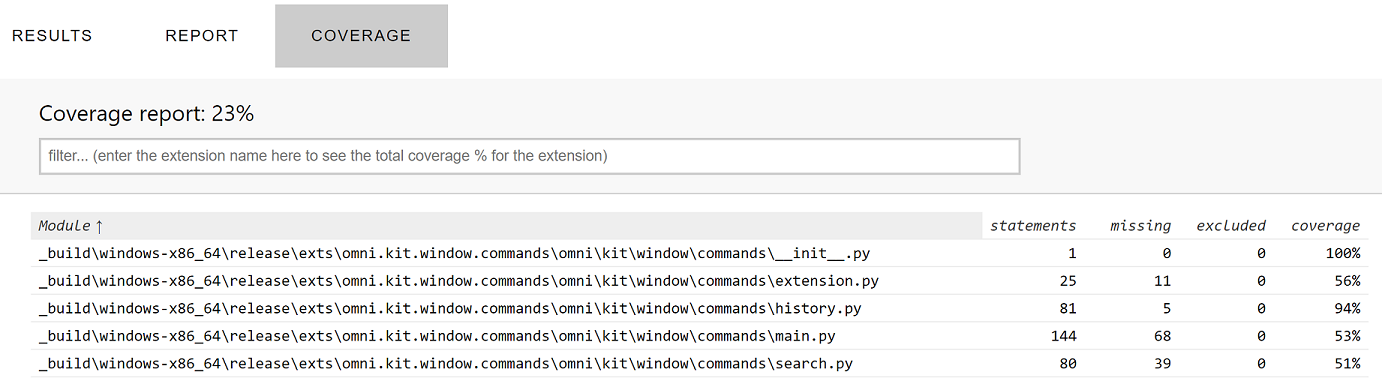
Based on the Google Code Coverage Best Practices the general guideline for extension coverage is defined as: 60% is acceptable, 75% is commendable and 90% is exemplary.
The settings to modify the Coverage behavior are found in the extension.toml file of omni.kit.test, for example pyCoverageThreshold to modify the threshold and filter flags like pyCoverageIncludeDependencies to modify the filtering.
Note: the python code coverage is done with Coverage.py. If you need to exclude code from Coverage you can consult this section.
The python code coverage is done with Coverage.py. If you need to exclude code from Coverage you can consult this section.
For example any line with a comment # pragma : no cover is excluded. If that line introduces a clause, for example, an if clause, or a function or class definition, then the entire clause is also excluded.
if example: # pragma: no cover
print("this line and the `if example:` branch will be excluded")
print("this line not excluded")
Debugging Coverage
If you see strange coverage results, the easiest way to understand what is going is to modify test_coverage.py from omni.kit.test. In def startup(self) comment out the source=self._settings.filter line and also remove all items in self._coverage.config.disable_warnings. Coverage will run without any filter and will report all warnings, giving more insights. List of warnings can be seen here.
Disabling a python test
Use decorators from unittest module, e.g.:
@unittest.skip("Fails on Linux now, to be fixed") # OM-12345
async def test_create_delete(self):
...
Pass extra cmd args to the test
To pass extra arguments for debugging purposes (for permanent use [[test]] config part) there are 2 ways:
all arguments after
--will be passed, e.g._build\windows-x86_64\release\tests-[extension_name].bat -- -v --/app/printConfig=1use
/exts/omni.kit.test/testExtArgssetting, e,g,:--/exts/omni.kit.test/testExtArgs/0="-v"
Choose an app to run tests in
All tests run in a context of an app, which by default is an empty app: "${kit}/apps/omni.app.test_ext.kit". You can instead pass your own kit file, where you can define any extra settings.
In this kit file you can change testing environment, enable some debug settings or extensions. omni.app.test_ext_kit_sdk.kit app kit comes with a few useful settings commented.
Test Output
For each test process, omni.kit.test provides a directory it can write test outputs to (logs, images, etc):
import omni.kit.test
output_dir = omni.kit.test.get_test_output_path()
Or using test_output token:
output_dir = carb.tokens.get_tokens_interface().resolve("${test_output}")
When running on CI this folder becomes a build artifact.
Python debugger
To enable python debugger you can use omni.kit.debug.python extension. One way is to uncomment in omni.app.test_ext.kit:
# "omni.kit.debug.python" = {}
You can use VSCode to attach a python debugger. Look into omni.kit.debug.python extension.toml for more settings, and check the FAQ section for a walkthrough.
Wait for the debugger to attach
If you want to attach a debugger, you can run with the -d flag. When Kit runs with -d, it stops and wait for debugger to attach, which can also can be skipped. Since we run 2 processes, you likely want to attach to the second one - skip the first one. E.g.:
λ _build\windows-x86_64\release\tests-example.python_ext.bat -d
[omni.kit.app] Waiting for debugger to attach, press any key to skip... [pid: 19052]
[Info] [carb] Logging to file: C:/projects/extensions/kit-template/_build/windows-x86_64/release//logs/Kit/kit/103.0/kit_20211018_160436.log
Test output path: C:\projects\extensions\kit-template\_testoutput
Running 1 Extension Test(s).
|||||||||||||||||||||||||||||| [EXTENSION TEST START: example.python_ext-0.2.1] ||||||||||||||||||||||||||||||
>>> running process: C:\projects\extensions\kit-template\_build\windows-x86_64\release\kit\kit.exe ${kit}/apps/omni.app.test_ext.kit --enable example.python_ext-0.2.1 --/log/flushStandardStreamOutput=1 --/app/name=exttest_example.python_ext-0.2.1 --/log/file='C:\projects\extensions\kit-template\_testoutput/exttest_example.python_ext-0.2.1/exttest_example.python_ext-0.2.1_2021-10-18T16-04-37.log' --/crashreporter/dumpDir='C:\projects\extensions\kit-template\_testoutput/exttest_example.python_ext-0.2.1' --/plugins/carb.profiler-cpu.plugin/saveProfile=1 --/plugins/carb.profiler-cpu.plugin/compressProfile=1 --/app/profileFromStart=1 --/plugins/carb.profiler-cpu.plugin/filePath='C:\projects\extensions\kit-template\_testoutput/exttest_example.python_ext-0.2.1/ct_exttest_example.python_ext-0.2.1_2021-10-18T16-04-37.gz' --ext-folder c:/projects/extensions/kit-template/_build/windows-x86_64/release/kit/extsPhysics --ext-folder c:/projects/extensions/kit-converters/_build/windows-x86_64/release/exts --ext-folder C:/projects/extensions/kit-template/_build/windows-x86_64/release/exts --ext-folder C:/projects/extensions/kit-template/_build/windows-x86_64/release/apps --enable omni.kit.test --/exts/omni.kit.test/runTestsAndQuit=true --/exts/omni.kit.test/includeTests/0='example.python_ext.*' --portable-root C:\projects\extensions\kit-template\_build\windows-x86_64\release\/ -d
|| [omni.kit.app] Waiting for debugger to attach, press any key to skip... [pid: 22940]
Alternatively, pass -d directly to the second process by putting it after --:
_build\windows-x86_64\release\tests-[extension_name].bat -- -d
Reading Logs
Each process writes own log file. Paths to those files are printed to stdout. You can run with -v to increase the verbosity of standard output.
Marking tests as unreliable
It is often the case that certain tests can fail randomly, with some probability. That can block CI/CD pipelines and lowers the trust into the TC state.
In that case:
Create a ticket with
Kit:UnreliableTestslabelMark a test as unreliable and leave the ticket number in the comment
Unreliable tests do not run as part of the regular CI pipeline. They run in the separate nightly TC job.
There are 2 ways to mark a test as unreliable:
Mark whole test process as unreliable:
[[test]] unreliable = true
Mark specific python tests as unreliable:
[[test]] pythonTests.unreliable = [ "*test_name" ]
Running unreliable tests
To run unreliable tests (and only them) pass --/exts/omni.kit.test/testExtRunUnreliableTests=1 to the test runner:
> _build\windows-x86_64\release\tests-example.python_ext.bat --/exts/omni.kit.test/testExtRunUnreliableTests=1
Listing tests
To list tests without running, pass --/exts/omni.kit.test/printTestsAndQuit=1. That will still take some time to start the tested extension. It is a limitation of the testing system that it can’t find tests without setting up python environment:
> _build\windows-x86_64\release\tests-example.python_ext.bat --/exts/omni.kit.test/printTestsAndQuit=1
Look for lines like:
|| ========================================
|| Printing All Tests (count: 6):
|| ========================================
|| omni.kit.commands.tests.test_commands.TestCommands.test_callbacks
|| omni.kit.commands.tests.test_commands.TestCommands.test_command_parameters
|| omni.kit.commands.tests.test_commands.TestCommands.test_commands
|| omni.kit.commands.tests.test_commands.TestCommands.test_error
|| omni.kit.commands.tests.test_commands.TestCommands.test_group
|| omni.kit.commands.tests.test_commands.TestCommands.test_multiple_calls
Accordingly, to list unreliable tests add --/exts/omni.kit.test/testExtRunUnreliableTests=1:
> _build\windows-x86_64\release\tests-example.python_ext.bat --/exts/omni.kit.test/testExtRunUnreliableTests=1 --/exts/omni.kit.test/printTestsAndQuit=1
repo_test: Running All Tests
To run all tests in the repo we use repo_test repo tool. Which is yet another process that runs before anything. It globs all the files according to repo.toml [repo_test] section configuration and runs them.
It is one entry point to run all sorts of tests. Different kinds of tests are grouped into suites. By default, it will run one suite, but you can select which suite to run with --suite [suite name]. Look at repo.toml for entries like [repo_test.suites.pythontests]. In that example: pythontests is a suite name.
You can also choose a build config to run tests on: -c release or -c debug. In kit the default is debug, in other repos: release.
Run all tests in the repo:
> repo.bat test
or
> repo.bat test --suite pythontests -c release
Just print them:
> repo.bat test -l
To filter tests:
> repo.bat test -f foobar
For more options (as usual):
> repo.bat test -h
Excluding Tests from TC
You can control which shell scripts to run with repo_test in repo.toml:
[[repo_test.suites.alltests.group]]
# Run all test
include = [
"tests-*${shell_ext}"
]
exclude = [
"tests-example.cpp_ext*", # Exclude some script
]
args = []
Check before running with:
> repo.bat test -l
Adding Info to Failed Test Summary
If a test fails, a summary is printed to stdout that looks like so:
[fail] Extension Test failed. Details:
Cmd: kit.exe ...
Return code: 13
Failure reasons:
Process return code: 13 != 0.
Failing tests: ['test_all (omni.example.ui.tests.example_ui_test.TestExampleUi)']
You can add more fields to this summary by printing special pragmas to stdout from your tests (in fact,
the Failing tests field above is done this way). For example, if you were to add the line
print("##omni.kit.test[set, foo, bah]") to the test above, then the summary would look like so:
[fail] Extension Test failed. Details:
Cmd: kit.exe ...
Return code: 13
Failure reasons:
Process return code: 13 != 0.
Failing tests: ['test_all (omni.example.ui.tests.example_ui_test.TestExampleUi)']
foo: bah
Pragma operations must appear at the start of a line. They should appear on their own, and any further pragmas on the same line will be ignored.
Available pragma operations are:
set: Set a field. Example:##omni.kit.test[set, foo, bah]append: Append to a list field. Example:##omni.kit.test[append, foo, bah]
Note that if a pragma fails for any reason (the syntax is incorrect; you try to append to a value that was previously set), it will be silently ignored.
omni.kit.ui_test: Writing UI tests
Many extensions build various windows and widgets using omni.ui. The best way to test them is by simulating user interactions with the UI. For that omni.kit.ui_test extension can be used.
omni.kit.ui_test provides a way to query UI elements and interact with them. To start add test dependency to this extension:
[[test]]
dependencies = [
"omni.kit.ui_test",
]
Now you can import and use it in tests. Example:
import omni.kit.ui_test as ui_test
async def test_button(self):
# Find a button
button = ui_test.find("Nice Window//Frame/**/Button[*]")
# button is a reference, actual omni.ui.Widget can be accessed:
print(type(button.widget)) # <class 'omni.ui._ui.Button'>
# Click on button
await button.click())
Refer to omni.kit.ui_test documentation for more examples and API.
(Advanced) Generating new tests or adapting discovered tests at runtime
Python unit tests are discovered at runtime. We introduced a way to adapt and/or extend the list of tests
by implementing custom omni.kit.test.AsyncTestCase class with def generate_extra_tests(self) method.
This method allows:
changes to discovered test case by mutating
selfinstancegeneration of new test cases by returning a list of them
In general, this method is preferred when same set of tests needs to be validated with multiple different configurations. For example, when developing new subsystems while maintaining the old ones.
Running Tests As Benchmarks
It is possible to run Python unit tests as benchmarks and forward the results to regression frameworks for automated regression detection. The following chapters will explain how to run, automate and write the benchmarks.
Writing Python Benchmarks
In order to write Python Benchmarks once can follow a very similar pattern as writing Python unit tests.
The only difference is, that one has to derive the from BenchmarkTestCase as base class and use benchmark instead of
test as prefix such that the benchmark methods get discovered.
Adding Samples of Custom Metrics per Benchmark
It is possible to set additional metrics during the runtime of a benchmark method.
One can do this for single value metrics or array metrics by calling the respective function of the BenchmarkTestCase base class:
def set_metric_sample(self, name: str, value: Union[int, float, bool], unit: Optional[str] = None):
"""
Set a sample for a custom metric. Providing the unit is optional.
"""
def set_metric_sample_array(self, name: str, values: Union[List[int], List[float], List[bool]], unit: Optional[str] = None):
"""
Set a sample array for a custom metric. Providing the unit is optional.
"""
Example Benchmark Python Code
import asyncio
from omni.kit.test import AsyncTestCase, BenchmarkTestCase
class TestBenchmarks(BenchmarkTestCase):
"""
Example Benchmark class with custom metrics.
* To use custom metrics one has to derive from `BenchmarkTestCase`.
* Benchmark methods have to start with the 'benchmark' prefix.
* The runtime of the benchmark methods and their skip state
belong to the default metrics which are always reported.
"""
def setUp(self):
pass
async def benchmark_sleepy_with_custom_metrics(self):
"""
Benchmark method using custom metrics.
"""
# sample for custom metric 'sleep_time' is set to 0.1s
self.set_metric_sample(name="sleep_time", value=0.1, unit="s")
await asyncio.sleep(0.1)
# sample for custom metric 'runs' is set to 1
self.set_metric_sample(name="runs", value=1)
async def benchmark_sleepy_with_custom_metrics_array(self):
"""
Another benchmark method using custom metrics to demonstrate setting arrays for a metric, and to show that
there's no crosstalk of metrics between benchmarks.
"""
# array of samples for custom metric 'my_other_metric' is set to [1.2ms, 0.9ms, 1.1ms]
self.set_metric_sample_array(name="my_other_metric", values=[1.2, 0.9, 1.1], unit="ms")
await asyncio.sleep(0.01)
CLI Parameters to Run Benchmarks Manually
The benchmark framework supports following CLI Parameters:
Parameter |
Description |
|---|---|
|
Enable Benchmark Framework: Runs only test methods which are prefixed with |
|
Set custom fingerprints which are passed to the output JSON file. Fingerprints are meant to describe the environment that runs the benchmarks such that regression frameworks can track and distinguish results by their fingerprints. The benchmark framework sets a couple of these fingerprints by default for you. For example the platform (e.g. |
To pass these CLI parameters to the unit test extension, one has to use the -- parameter.
Example Command
repo.bat test -- --benchmark --/exts/omni.kit.test/benchmarkFingerPrint/GPU=G80