Data IoT#
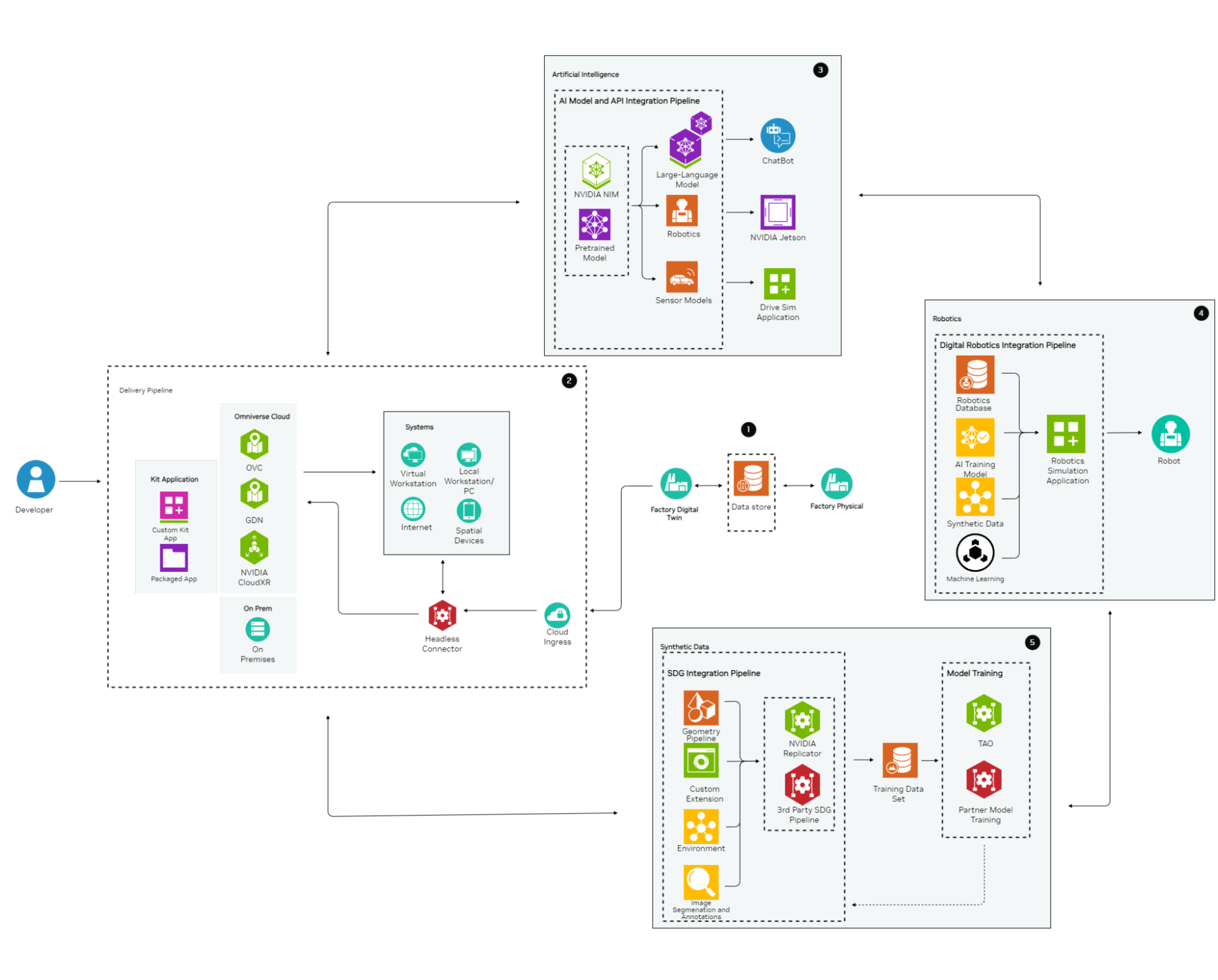
The following highlights the details of the integration of Data/IoT for a Factory Digital Twin. This architectural diagram categorizes and organizes Data/IoT integration across Artificial Intelligence, Robotics, and Synthetic Data. It is built around a straightforward design of the Data/IoT Pipeline, demonstrating how each category contributes to the overall functionality and efficiency of the digital twin. By leveraging advanced technologies, this architecture aims to enhance production processes, optimize data management, and improve predictive capabilities within a factory setting.
Pipeline Integration#
Digital Pipeline Integration#
Starting with a physical factory, data is captured in real-time through various means and integrated into the digital pipeline through a structured database. This database is passed into the digital twin factory for ingestion through a Custom Kit Application. This comprehensive approach ensures seamless data flow and optimization throughout the factory’s digital ecosystem.
Delivery Pipeline#
The delivery pipeline utilizes a Custom Omniverse Kit Application, enabling developers to create a tailored digital pipeline for the specific services required by the factory. Data can be ingested through MQTT Brokers into a Headless Connector, allowing cloud registries to integrate consistently into the Omniverse Kit application. This application is delivered as a clean and secure package through both cloud and local services, ensuring seamless data ingestion for on-premises and off-premises environments. This approach guarantees a flexible, secure, and efficient integration of digital services into the factory’’s operations.
Data/IoT#
Synthesizing real-time and synthetic data for integration into a Digital Twin can be achieved through various methods. This includes leveraging AI across Large Language Models (LLMs), robotics, and sensor models, integrating AI, real-time data, and synthetic data with Machine Learning APIs, machine-to-machine networks (MQTT), and OPC-UA to optimize robotics in a training platform. Additionally, deploying highly intelligent synthetic data enhances the training processes, ensuring robust and comprehensive development of the digital twin environment.
Artificial Intelligence#
Integrating real-time and synthetic data to train models using Enterprise AI Microservices like NVIDIA NIM or your own pre-trained models, the AI pipeline extends across multiple applications.
Large-Language Models/Visual-Language Models: Deploy advanced algorithms using the LLM/VLM pipeline to support chatbots, enabling internal employees to perform their tasks more efficiently and assist customers with end-use products and services.
Robotics Pipeline Integration: Deploy trained models into the robotics pipeline to optimize and train digital twins of factory robots. Utilize NVIDIA Jetson to bring this data into real-world applications.
Sensor Model Training for Autonomous Vehicles: Use the trained model to assist in training a Sensor Model for Drive Sim Applications, facilitating the training of autonomous vehicles in a simulated environment.
Robotics#
The integration of robotics with Data/IoT is streamlined by leveraging subsets from various pipelines within the Factory Digital Twin Architecture, including the use of Cloud Ingress APIs and OPC-UA to exchange data from sensors to cloud applications.
Foundation with Real-Time Robotics Data: Establish a robust database of real-time robotics data, enabling the training platform to utilize specific datasets and scenarios reflective of the physical factory environment.
AI Model Integration: Incorporate an AI model into the pipeline to train and optimize robots effectively within the training platform.
Utilization of Synthetic Data: Employ synthetic data alongside the robotics database, leveraging data exchange using OPC-UA standards, and AI models to train robots on potential scenarios they might encounter in a physical environment, without real-world exposure.
Machine Learning and Reinforcement Learning: Implement machine learning algorithms and reinforcement learning using APIs, synthetic data, and artificial intelligence to accelerate and enhance the efficiency of robot deployment.
Synthetic Data#
When training in a simulated environment, real-time data may not always be sufficient to simulate every scenario. In cases where data is scarce, too dangerous to capture in real-time, or nonexistent, synthetic data can bridge the gap.
Utilize the Geometry Pipeline: Create simulation-ready assets that accurately represent the physical factory.
Integrate Custom Omniverse Extensions: Seamlessly bring in and process data for enhanced simulation fidelity.
Develop a Processing Environment: Establish a robust environment for handling and processing simulations efficiently.
Implement Image Segmentation and Annotations: Use these techniques to identify key elements and improve overall throughput in your simulations.
Conclusion#
This reference architecture guide presents a comprehensive approach to implementing a digital twin for a factory, leveraging advanced AI and machine learning technologies. By capturing and integrating real-time data into a structured database and utilizing a Custom Omniverse Kit Application, seamless data flow and optimization are ensured throughout the factory’s digital ecosystem. The architecture employs AI across Large Language Models, robotics, and sensor models to enhance training platforms, deploy chatbots, optimize robotic functions, and train autonomous vehicles. Synthetic data bridges gaps where real-time data is insufficient, supporting robust simulations and training. Overall, this guide offers a flexible framework for integrating cutting-edge technologies to improve efficiency, workflows, and decision-making in manufacturing.